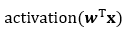1. 임베딩
원핫인코딩(One-Hot-Encoding)은 머신러닝, 그중에서도 범주형 데이터(categorical data)에 많이 사용하는 기법입니다. 예를 들어, 음식에 대한 데이터가 있을 때 종류를 구분한다면 '한식', '중식', '일식', '이탈리아' 등과 같이 구분할 수 있습니다. 원핫인코딩은 이런 상황에서 아래 표처럼 표기하게 됩니다.
| 종류_한식 | 종류_중식 | 종류_일식 | 종류_이탈리아 |
|---|---|---|---|
| 1 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 1 |
하지만 NLP에서 이러한 방법은 효과적이지 않은데, 굉장히 다양한 단어들을 표현해야하는 NLP에서 원핫인코딩은 데이터의 표현이 희소(Sparse)하여 특정 행/열에서 무의미한 0 만 존재하고 이는 데이터가 너무 많아져 비효율적인 연산을 가져올 수 있습니다. 또한, 1과 0으로 구분하는 원핫인코딩으로는 유사한 의미에 대해서도 표현이 불가합니다. 그래서 NLP에서는 임베딩이라는 다른 방식을 사용합니다.
임베딩은 쉽게 이야기하면 컴퓨터가 자연어를 이해할 수 있도록 숫자의 나열인 벡터로 바꾸는 과정을 이야기 합니다. 수학적으로 이야기하자면, 원본 데이터에 임베딩 행렬을 곱해서 표현합니다. 이렇게 표현한 임베딩은 다양한 역할을 수행할 수 있습니다.
- 차원축소
원핫인코딩에서 지적했던 희소한 데이터 포인트들을 좀 더 밀집(Dense)되게 표현하고 그 결과로 차원을 축소할 수 있습니다. 이는 연산의 효율성을 도모할 수 있습니다. - 의미함축
또한, 원핫인코딩은 의미에 대해서 표현이 불가능하다고 했지만, 임베딩은 의미를 담을 수 있습니다. 단어의 의미, 문법 정보를 함축하여 단어 혹은 문장 사이의 관련도를 담을 수 있다는 의미입니다. 단어 벡터의 의미를 담고 있기 때문에 '한국-서울+도쿄' 연산을 수행하면 '일본'이라는 결과를 도출할 수 있습니다. 이에 대한 재밌는 실험은 아래 링크를 통해 시도해 볼 수 있습니다.
- 전이학습
전이학습이란 임베딩을 다른 딥러닝 모델의 입력값으로 쓰는 것을 일컫습니다. 이미 대규모 말뭉치를 활용해 만들어둔 검증된 임베딩을 활용할 수 있다면, 훨씬 효율적으로 사용할 수 있을텐데 임베딩은 이러한 전이학습이 가능하기 때문에 효율적입니다.
2. Word2Vec
자연어 처리에서 분포는 특정 범위(또는 '윈도우')에서 동시에 등장하는 단어들의 집합(문맥)을 의미합니다. 이 집합에서 자주 등장하는 경우 의미가 유사할 것이라는 가정을 분포 가정이라 합니다.
임베딩에 대한 기법 중 Word2Vec는 위에서 언급한 분포 가정의 대표적인 모델입니다. 구글 연구 팀에서 2013년에 발표(링크)한 임베딩 기법으로, 방식은 CBOW와 Skip-Gram 두가지로 구분됩니다. CBOW는 Continuous Bag-Of-Words의 준말로 문맥 단어들을 가지고 타깃을 예측하는 모델입니다. Skip-Gram은 타깃 단어로부터 문맥을 예측하는 모델입니다. 예를 들면, CBOW는 'she is a beautiful'라는 문맥에서 'girl'이라는 타깃을 예측합니다. 반면, Skip-Gram에서는 'girl'이라는 단어에서 'she is a beautiful' 이라는 문맥을 예측합니다.
여기서는 더 큰 규모의 데이터셋에 적합한 Skip-Gram에 대해 살펴보고자 합니다. Skip-Gram 모델은 다음과 같은 과정을 거칩니다.
(1) 먼저 문맥을 정의합니다.
문맥은 윈도우에 의해 정의됩니다. 윈도우는 타깃단어의 양 쪽으로 확장되는 것으로 볼 수 있습니다. Google에서 제시하고 있는 예시를 통해 이해해보겠습니다.

밑줄 친 단어는 타깃단어로 윈도우를 2개로 지정하면서 양 옆 두개 단어까지 확장하고 있는 것을 확인할 수 있습니다. 타깃단어와 문맥단어를 쌍으로 연결하는 Skip-gram 열에서 볼 수 있습니다.
(2) Negtive Sample을 형성합니다.
Negative Sample이란 타깃 단어와 그 주변에 없는 단어(noise; 텍스트에서 임의 추출)의 쌍을 말합니다. 반대로, Positive Sample은 타깃 단어와 그 주변에 있는 단어의 쌍을 말합니다. 위의 예시에서 임의의 네거티브 샘플을 추출하면 다음과 같습니다.
(hot, shimmered)
(wide, hot)
(wide, sun)
Skip-Gram에서는 이렇게 같은 텍스트에서 많은 학습 데이터를 만들 수 있습니다.
(3) 실제 단어에는 높은 확률을 부여하고, 그렇지 않은 단어들에는 낮은 확률을 부여하도록 합니다. (Negative Sampling)
3. Word2Vec 구현
그렇다면 이를 실제로 코드로 구현해보고자 합니다. 전반적인 설명을 하다보니 내용이 꽤 길어서 실제 예제에 적용하는 것만 보고 싶으신 분은 우측 상단에서 3.3 후반 ~ 6까지로 이동하셔서 확인하시기 바랍니다. 모든 예제 소스들은 Google Tenflow 팀의 홈페이지의 Word2Vec에 예시를 참고하였습니다. (링크)
3.1. 기본 준비 및 벡터화
import io
import re
import string
import tqdm
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
# Vectorize
sentence = "The wide road shimmered in the hot sun"
tokens = list(sentence.lower().split())
vocab, index = {}, 1 # start indexing from 1
vocab['<pad>'] = 0 # add a padding token
for token in tokens:
if token not in vocab:
vocab[token] = index
index += 1
vocab_size = len(vocab)
print(vocab)
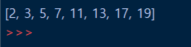
example_sequence = [vocab[word] for word in tokens]
print(example_sequence)우선 Word2Vec 구현을 위해 필요한 라이브러리를 호출하였습니다. 예시로 사용하는 텍스트를 정의하고 어휘집합을 딕셔너리 형태로 만듭니다. 그리고 문장을 인덱스로 이용해 벡터화 합니다. 그에 대한 출력 결과는 아래와 같습니다.

3.2. Skip-gram 및 Negative Sampling
window_size = 2
positive_skip_grams, _ = tf.keras.preprocessing.sequence.skipgrams(
example_sequence,
vocabulary_size=vocab_size,
window_size=window_size,
negative_samples=0)위에서 설명했던 것처럼 Skip-gram은 네거티브 샘플을 형성할 필요가 있습니다. 텐서플로우에서는 이 귀찮은 과정을 해결하기 위해 tf.keras.preprocessing.sequence.skipgrams로 지원합니다. skipgrams 함수는 모든 Skip-gram 쌍을 주어진 윈도우 크기만큼 슬라이딩하면서 반환합니다.
그 다음으로는 네거티브 샘플링을 위한 코드입니다. 훈련을 위해서 더 많은 쌍을 만들기 위해서는 어휘집합으로부터 임의의 단어들을 뽑아낼 필요가 있습니다. tf.random.log_uniform_candidate_sampler 함수는 num_ns로 표기되는 네거티브 샘플 개수만큼 샘플링 합니다.
# Get target and context words for one positive skip-gram.
target_word, context_word = positive_skip_grams[0]
# Set the number of negative samples per positive context.
num_ns = 4
context_class = tf.reshape(tf.constant(context_word, dtype="int64"), (1, 1))
negative_sampling_candidates, _, _ = tf.random.log_uniform_candidate_sampler(
true_classes=context_class, # class that should be sampled as 'positive'
num_true=1, # each positive skip-gram has 1 positive context class
num_sampled=num_ns, # number of negative context words to sample
unique=True, # all the negative samples should be unique
range_max=vocab_size, # pick index of the samples from [0, vocab_size]
seed=SEED, # seed for reproducibility
name="negative_sampling" # name of this operation
)참고로 작은 데이터 셋에는 num_ns = [ 5, 20 ] 사이의 값이 적당할 수 있으며, 큰 데이터셋에는 num_ns = [ 2, 5 ] 사이의 값이 충분하다고 알려져있습니다.
3.3. 훈련 데이터셋 구성 및 요약
# Add a dimension so you can use concatenation (in the next step).
negative_sampling_candidates = tf.expand_dims(negative_sampling_candidates, 1)
# Concatenate a positive context word with negative sampled words.
context = tf.concat([context_class, negative_sampling_candidates], 0)
# Label the first context word as `1` (positive) followed by `num_ns` `0`s (negative).
label = tf.constant([1] + [0]*num_ns, dtype="int64")
# Reshape the target to shape `(1,)` and context and label to `(num_ns+1,)`.
target = tf.squeeze(target_word)
context = tf.squeeze(context)
label = tf.squeeze(label)학습용 데이터셋을 만드는 과정을 요약한 다이어그램은 아래와 같습니다.

'the', 'is', 'on'과 같은 단어들은 흔히 발견할 수 있지만, 의미를 해석하는데 유용한 정보를 제공하지는 않습니다. 따라서 임베딩의 품질을 높이기 위해 단어별 가중치를 주는 작업이 필요합니다.
sampling_table = tf.keras.preprocessing.sequence.make_sampling_table(size=10)make_sampling_table 함수는 확률론적 샘플링 테이블을 기반으로 단어의 빈도 순위를 생성합니다. sampling_table[i]는 i번째의 가장 빈번하게 등장하는 단어의 확률을 나타냅니다.
다음은 훈련데이터의 생성입니다. 이 함수는 뒤에서 사용될 예정입니다.
# Generates skip-gram pairs with negative sampling for a list of sequences
# (int-encoded sentences) based on window size, number of negative samples
# and vocabulary size.
def generate_training_data(sequences, window_size, num_ns, vocab_size, seed):
# Elements of each training example are appended to these lists.
targets, contexts, labels = [], [], []
# Build the sampling table for `vocab_size` tokens.
sampling_table = tf.keras.preprocessing.sequence.make_sampling_table(vocab_size)
# Iterate over all sequences (sentences) in the dataset.
for sequence in tqdm.tqdm(sequences):
# Generate positive skip-gram pairs for a sequence (sentence).
positive_skip_grams, _ = tf.keras.preprocessing.sequence.skipgrams(
sequence,
vocabulary_size=vocab_size,
sampling_table=sampling_table,
window_size=window_size,
negative_samples=0)
# Iterate over each positive skip-gram pair to produce training examples
# with a positive context word and negative samples.
for target_word, context_word in positive_skip_grams:
context_class = tf.expand_dims(
tf.constant([context_word], dtype="int64"), 1)
negative_sampling_candidates, _, _ = tf.random.log_uniform_candidate_sampler(
true_classes=context_class,
num_true=1,
num_sampled=num_ns,
unique=True,
range_max=vocab_size,
seed=seed,
name="negative_sampling")
# Build context and label vectors (for one target word)
negative_sampling_candidates = tf.expand_dims(
negative_sampling_candidates, 1)
context = tf.concat([context_class, negative_sampling_candidates], 0)
label = tf.constant([1] + [0]*num_ns, dtype="int64")
# Append each element from the training example to global lists.
targets.append(target_word)
contexts.append(context)
labels.append(label)
return targets, contexts, labels3.4. 학습 데이터 임포트
그러면 실전으로 들어가겠습니다. Word2Vec 모델을 활용해 문장 모음들을 훈련 모델을 생성해보겠습니다. 활용할 데이터는 TensorFlow에서 제공하는 셰익스피어 텍스트 입니다. 앞서 벡터화했던 방법과는 다르게, TextVectorization 레이어를 통해 텍스트를 벡터화를 했습니다.
path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')
# 비어있는 줄 제거
text_ds = tf.data.TextLineDataset(path_to_file).filter(lambda x: tf.cast(tf.strings.length(x), bool))
# 소문자 활용 및 구두점 제거
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
return tf.strings.regex_replace(lowercase,
'[%s]' % re.escape(string.punctuation), '')
vocab_size = 4096
sequence_length = 10
# TextVectorization
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)TextVectorization.adapt를 통해 어휘 집합을 생성하고, TextVectorization.get_variable 을 통해 레이어가 말뭉치를 나태내도록 할 수 있습니다. get_variable 함수는 어휘집합의 토큰을 많이 등장하는 내림차순에 따라 리스트를 반환합니다. 그리고 이 과정을 거치게 되면, 벡터를 형성할 수 있습니다.
vectorize_layer.adapt(text_ds.batch(1024))
invers_vocab = vectorize_layer.get_vocabulary()
# Vectorize the data in text_ds.
text_vector_ds = text_ds.batch(1024).prefetch(AUTOTUNE).map(vectorize_layer).unbatch()Word2Vec 모델에 훈련하기 위해서 벡터 시퀀스 리스트로 만듭니다. 이는 positive & negative samples를 만들기 위해 필요합니다. 앞서 만들었던 generate_training_data 함수를 활용해 Word2Vec 모델에 들어갈 값들을 계산합니다.
sequences = list(text_vector_ds.as_numpy_iterator())
targets, contexts, labels = generate_training_data(
sequences=sequences,
window_size=2,
num_ns=4,
vocab_size=vocab_size,
seed=SEED)
targets = np.array(targets)
contexts = np.array(contexts)[:,:,0]
labels = np.array(labels)
BATCH_SIZE = 1024
BUFFER_SIZE = 10000
dataset = tf.data.Dataset.from_tensor_slices(((targets, contexts), labels))
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)3.5. 모델링
Word2Vec 모델을 서브클래싱 API를 통해 작성할 수 있습니다. 각 레이어별로 설명은 다음과 같습니다.
- target_embedding : 타깃단어로 나타나는 단어의 임베딩을 찾는 레이어 입니다. 파라미터의 개수는 vocab_size * embedding_dim 으로 계산할 수 있습니다.
- context_embedding : 문맥단어로 나타나는 단어의 임베딩을 찾는 레이어 입니다. 파라미터의 개수는 vocab_size * embedding_dim 으로 계산할 수 있습니다.
class Word2Vec(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim):
super(Word2Vec, self).__init__()
self.target_embedding = layers.Embedding(vocab_size,
embedding_dim,
input_length=1,
name="w2v_embedding")
self.context_embedding = layers.Embedding(vocab_size,
embedding_dim,
input_length=num_ns+1)
def call(self, pair):
target, context = pair
if len(target.shape) == 2:
target = tf.squeeze(target, axis=1)
word_emb = self.target_embedding(target)
context_emb = self.context_embedding(context)
dots = tf.einsum('be,bce->bc', word_emb, context_emb)
return dots
# Loss function
def custom_loss(x_logit, y_true):
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x_logit, labels=y_true)여기서는 카테고리 크로스엔트로피를 네거티브 샘플링의 손실함수로 정의했습니다. 그럼 이제 모든 준비가 끝났습니다. 갖고있는 데이터를 Word2Vec 모델에 적용하도록 하겠습니다.
embedding_dim = 128
word2vec = Word2Vec(vocab_size, embedding_dim)
word2vec.compile(optimizer='adam',
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
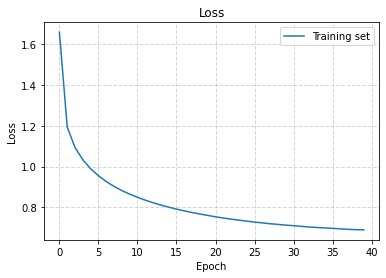
word2vec.fit(dataset, epochs=20, callbacks=[tensorboard_callback])3.6. 임베딩 분석
모델의 가중치는 Model.get_layer와 Layer.get_weights를 통해 확인할 수 있습니다. 그리고 위 과정을 통해 만든 벡터와 메타데이터 파일도 저장할 수 있습니다.
weights = word2vec.get_layer('w2v_embedding').get_weights()[0]
# Save vectors & metadata files
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
# Download vector
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass'Python > Data Analysis' 카테고리의 다른 글
| [PyTorch] PyTorch를 활용한 텐서 모양 바꾸기 (0) | 2024.08.09 |
|---|---|
| [PyTorch] PyTorch를 활용한 텐서 생성하기 (0) | 2024.08.09 |
| [NLP] Char-RNN 을 활용하여 언어 모델링 실습 | 텍스트 생성 (1) | 2022.06.06 |
| [NLP] N-gram 모델 구현하기 기초 | 임베딩, NLTK (1) | 2022.05.30 |
| TensorFlow로 딥러닝 모델 구현하기 | 시퀀셜, 함수형, 서브클래싱 API (1) | 2022.05.17 |