
1. 개요
1.1. PyTorch 개요
PyTorch는 대표적인 Python을 위한 딥러닝 프레임워크로 Facebook에서 개발을 진행했다. Google에서 개발한 또 다른 프레임워크인 TensorFlow도 있는데, 둘 다 많이 사용된다. 실제로 갖고 있는 책(Hands-On Machine Learning)의 경우 TensorFlow를 기반으로 설명하고 있고, 현재 참여하고 있는 교육과정이나 다른 강의들에서는 PyTorch를 기반으로 설명하고 있다.
PyTorch의 대표적인 특징은 동적 계산 그래프(Define-by-Run)의 형태를 띈다는 점이다. '계산 그래프'는 일련의 연산 과정을 그래프로 나타난 것[2]이고, '동적'의 의미는 계산 그래프의 생성 단계와 훈련 데이터를 입력하고 손실함수를 계산하는 단계를 같이 진행한다는 뜻이다. Define-by-Run이 동작하는 방식에 대한 개요는 아래 그림과 같다. [3]

Define-by-Run의 장점은 계산이 진행되면서 계산 그래프가 새롭게 생성하게 되기 때문에 유연하게 적용이 가능하다. [4]
1.2. 텐서의 정의
딥러닝을 배우다보면 텐서(Tensor)라는 개념이 많이 나온다. 학술적으로 엄밀하지는 않지만 위키피디아에서 텐서의 개념에 대해 살펴보면, 텐서는 다중선형대수학에서 다뤄지는 대상이다. [5] 이공계열 대학 교육과정에서 많이 배우는 선형대수학에서 다루는 벡터와 행렬에서 더 나아간 것이라고 생각할 수 있다.
- 0차원 : 스칼라
- 1차원 : 벡터
- 2차원 : 행렬
- 3+차원 : 텐서
2. 텐서의 생성
2.1. Version
우선 아래에서 나오는 코드는 PyTorch를 불러온 상태에서 실행 가능하므로 import를 통해 가져온다. Python과 PyTorch 버전은 아래와 같다.
import torch
import sys
print("Python version : ", sys.version)
print("PyTorch version : ", torch.__version__)

2.2. torch.tensor
텐서는 torch.tensor(데이터) 를 통해 생성 가능하다. 여기서 입력받는 '데이터'는 리스트, 튜플, ndarray(NumPy), 스칼라 값 등이 가능하다.
print(torch.tensor([1,2,3]))

또한, torch.tensor에서 입력할 수 있는 인자는 데이터 유형을 정할 수 있는 dtype, 기기를 할당하는 device 등이 있다.
2.3.텐서 데이터 유형 지정
PyTorch에서 사용가능한 데이터 유형은 아래와 같다. [6]
| Data Type | dtype = | Legacy |
| 32-bit floating point | torch.float32 or torch.float | torch.*.FloatTensor |
| 64-bit floating point | torch.float64 or torch.double | torch.*.DoubleTensor |
| 64-bit complex | torch.complex64 or torch.cfloat | |
| 128-bit complex | torch.complex128 or torch.cdouble | |
| 16-bit floating point 1 | torch.float16 or torch.half | torch.*.HalfTensor |
| 16-bit floating point 2 | torch.bfloat16 | torch.*.BFloat16Tensor |
| 8-bit integer (unsigned) | torch.uint8 | torch.*.ByteTensor |
| 8-bit integer (signed) | torch.int8 | torch.*.CharTensor |
| 16-bit integer (signed) | torch.int16 or torch.short | torch.*.ShortTensor |
| 32-bit integer (signed) | torch.int32 or torch.int | torch.*.IntTensor |
| 64-bit integer (signed) | torch.int64 or torch.long | torch.*.LongTensor |
| Boolean | torch.bool | torch.*.BoolTensor |
텐서에 담기는 데이터 유형을 지정하는 방법은 입력 인자에 'dtype ='에 위 표의 두번째 열에 있는 값을 넣어서 최초 데이터 생성에서 데이터 유형을 지정하는 방법이다.
a = torch.tensor([1,2,3])
print(a.dtype)
b = torch.tensor([1,2,3], dtype = torch.float64)
print(b)
print(b.dtype)

두번째 방법은 '타입캐스팅'이라고 불리는 데이터 유형을 바꾸는 것이다. 텐서에 데이터 타입 메서드(float, double, int, short, long)를 직접 활용하는 방법과 to()메서드에 dtype을 지정하는 방법이 있다.
print(a.dtype)
print(a.float().dtype)
print(a.double().dtype)
print(a.int().dtype)
print(a.short().dtype)
print(a.long().dtype)
print(a.to(dtype = torch.float64).dtype)

2.4. 0, 1 텐서 생성
모든 값이 0으로 이루어진 텐서는 torch.zeros(텐서 사이즈) 또는 torch.zeros_like(텐서)를 통해 만들 수 있다.
- 텐서 사이즈 : 생성하고 싶은 텐서의 사이즈 (예를 들어, 2 x 3 행렬을 원할 경우 2,3 입력)
- 텐서 : 어느 텐서와 같은 사이즈의 0 텐서를 생성하고 싶을 경우 입력
둘의 결과값은 거의 유사하지만, zeros_like는 입력받은 텐서의 dtype을 유지하고, zeros는 dtype 기본값 (보통 float32)을 따라가기 때문에 데이터 타입에 민감한 경우 주의해서 사용할 필요가 있다. 물론 메서드의 입력 인자로 dtype = 을 지정해주면 큰 차이 없이 사용할 수 있다.
모든 값이 1로 이뤄진 텐서를 만드는 torch.ones와 torch.ones_like는 0과 사용방법은 동일하다.
# tensor 생성
zero = torch.zeros(2,3)
one = torch.ones(2,3)
print(zero)
print(one)
# tensor를 입력받아 초기화된 tensor 생성
print(torch.ones_like(zero))
print(torch.zeros_like(one))

2.5. rand 텐서 생성
난수(random number) 생성은 0~1 사이 값으로 이뤄진 난수와 표준정규분포('n'ormal distributio)를 따르는 (크기는 매우 달라질 수 있음) 난수가 존재한다. 여기도 텐서 사이즈를 넣는 것과 텐서를 넣는 방법이 존재한다.
- 0~1 : torch.rand(사이즈), torch.rand_like(텐서)
- 표준정규분포 : torch.randn(사이즈), torch.randn_like(텐서)
# 난수 생성
print(torch.rand(3))
print(torch.randn(3))
print(torch.rand(2,3))
# tensor를 입력받아 난수 생성
print(torch.rand_like(zero))
print(torch.randn_like(zero))

2.6. torch.arange
파이썬에서는 range() 함수를 통해 특정 범위의 배열을 생성할 수 있다. PyTorch에서도 이와 유사하게 특정 범위의 텐서를 생성하는 arange(start, end, step)으로 생성할 수 있다.
print(torch.arange(10))
print(torch.arange(1,10,2))
2.7. Empty 텐서 생성과 값 입력
empty 텐서는 torch.empty(사이즈)를 통해, empty_like(텐서)를 통해 초기화되지 않은(uninitialized) 텐서를 생성할 수 있다. empty 텐서의 효용은 0-텐서, 1-텐서처럼 초기화된 텐서를 생성하는데 사용하는 메모리를 절약할 수 있다는 점이다.
empty = torch.empty(2,3)
print(empty)
이렇게 만들어진 empty 텐서에 특정한 값을 넣는 메서드는 fill_가 있다. 해당 메서드는 별도의 반환값이 존재하지 않고 해당 변수에 값이 입력되는 연산이라 동일한 메모리를 갖는 것을 확인할 수 있다.
# id(obj) : 파이썬 내장함수로 해당 객체(obj)의 메모리 주소를 반환
print("empty id : ", id(empty))
print(empty.fill_(3))
print("empty.fill_ id : ", id(empty.fill_(3)))

2.8. 텐서 복사하기
때로는 똑같은 텐서를 새롭게 만들어서 사용해야 할 수 있다. 복사하는 방법은 clone()과 detach() 메서드 두가지가 있는데, 둘 사이의 중요한 차이점은 detach() 메서드는 기존에 사용하고 있던 계산 그래프에서 분리해서 저장한다는 점이다. 앞서 설명한 것처럼 PyTorch는 Define-by-Run 방식이기 때문에 계산 그래프에서 분리하는 것은 기존 계산 결과에서 분리할 수 있음을 의미합니다.
# 복사하기
a = torch.tensor([1,2,3])
b = a.clone()
print(b)
c = a.detach()
print(c)2.9. 텐서 정보 확인하기
텐서에 담겨있는 데이터 이외에 연산을 수행하기 위해 중요한 정보 중 하나는 텐서의 사이즈입니다. 텐서의 사이즈를 보는 방법은 텐서의 속성 값인 .shape를 쓰는 방법과 메서드인 .size()를 사용하는 방법이 있습니다. 유사하게, 데이터 타입을 보는 방법도 속성값을 통해 확인할 수 있습니다.
a = torch.tensor([1,2,3])
print(a.size())
print(a.shape)
print(a.dtype)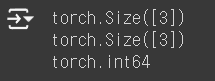
딥러닝 프레임워크의 장점 중 하나는 GPU 연산을 쉽게 지원한다는 것입니다. PyTorch의 주요 객체들은 어느 device에 올라가는지를 입력받기 때문에 속성에 접근함으로써 디바이스를 확인할 수 있습니다. 실행 환경에서는 GPU를 지원하고 있지 않아서 False로 나오는 것을 확인할 수 있습니다.
print(a.device)
print(torch.cuda.is_available())
만약, GPU 지원을 할 경우 아래와 같은 코드를 통해 디바이스를 변경할 수 있습니다. 다만, to()와 cuda()의 미묘한 차이가 있기 때문에 주의는 필요합니다.[7]
# GPU 할당
a.to('cuda')
a.cuda()
# CPU 할당
a.to(device='cpu')
a.cpu()
3. 참고자료
[1] 위키백과:PyTorch
[2] https://compmath.korea.ac.kr/deeplearning/BackPropagation.html
[3] https://www.oreilly.com/content/complex-neural-networks-made-easy-by-chainer/
[4] https://wikidocs.net/209706
[5] 위키백과:텐서
[6] https://pytorch.org/docs/stable/tensor_attributes.html#torch.dtype
[7] https://velog.io/@hyungraelee/net.todevice-vs-net.cuda
4. 수정사항
'Python > Data Analysis' 카테고리의 다른 글
| [PyTorch] 파이토치 메서드로 텐서의 연산 수행하기 (0) | 2024.08.16 |
|---|---|
| [PyTorch] PyTorch를 활용한 텐서 모양 바꾸기 (0) | 2024.08.09 |
| [NLP] 임베딩과 Word2Vec 실습해보기 (0) | 2022.09.07 |
| [NLP] Char-RNN 을 활용하여 언어 모델링 실습 | 텍스트 생성 (0) | 2022.06.06 |
| [NLP] N-gram 모델 구현하기 기초 | 임베딩, NLTK (0) | 2022.05.30 |