
이전에 파이썬을 활용해 정부 보도자료를 크롤링하는 게시글을 올린 적이 있다. 이 블로그내 제법 인기글 중 하나인데, 그만큼 많은 분들이 관심을 갖고 있다는 뜻이기도 할 것이다. 워낙 프로토타입 형태로 올렸던 글이라, 아주 간단한 형태의 크롤링만 올렸었다. 관련 링크는 아래에 첨부하였다.
2020.02.23 - [Python/Web Crawling] - 파이썬으로 정부 보도자료 크롤링 하기 (Web crawling)
파이썬으로 정부 보도자료 크롤링 하기 (Web crawling)
우리나라의 사회/산업/경제 전반적인 상황을 보기위해 신문도 참고할 자료 중 하나이긴 하지만, 각 정부 부처에서 제공하는 보도자료가 사실에 근접해서 보기에 훨씬 유용한 자료라 생각한다.
seanpark11.tistory.com
지금 돌이켜봤을 때, 위글에서 아쉬웠던 점이 몇 가지가 있는데 아래처럼 요약할 수 있을 것이다.
1. requests란 훌륭한 라이브러리를 놔두고, urllib3를 사용했다는 점 (urllib이 파이썬 내장 라이브러리긴 하지만, 공식 홈페이지에서도 requests를 사용할 것을 장려하는 점을 고려하면 새로운 내용으로 바꾸는 것이 적절할 것)
2. 한번에 한 페이지의 내용만 가져오는 것을 이야기함
3. 동적으로 움직이는 반응형 웹사이트는 위 테크닉만으로는 어려운데, 새로운 기술에 대한 소개 필요
이중에서 이번 글을 통해 두가지를 해결할 수 있을 것 같은데, 그중 하나인 1번은 앞으로 크롤링하는데 자연스럽게 사용하면서 녹여낼 것이고 나머지 하나인 2번은 오늘 이야기할 페이지네이션을 통해 해결하고자 한다. 나머지 세번째는 셀레니움(Selenium)으로 일반적으로 해결할텐데, 이는 나중 글에서 논하고자 한다.
우선, 페이지네이션에 대해 살펴봐야 할텐데, 검색창을 통해 알아보면 페이지네이션은 웹개발에서 DB의 많은 정보를 한꺼번에 표현하기 어려우므로 페이지의 형태로 표현하는 것을 지칭한다. (게시판 등에서 쉽게 볼 수 있는 형태라 어렵진 않다) 이건 개발, 그중에서도 백엔드 단에서 하는 이야기이고, 우리가 관심있는 크롤링에서는 어떻다고 이야기할 수 있을까? 정확한 정의는 아직 찾지는 못했지만, 페이지 형태로 구현된 정보들을 페이지(일련번호)를 부여하면서 읽어온다고 이야기할 수 있을 것이다.
이전에 봤던 기획재정부 보도자료 홈페이지를 들어가보자. 가장 아래로 가보면 "1 2 3 4 5" 상자로 이뤄진 페이지로 갈 수 있는 박스가 있는 것을 확인할 수 있다. 이 상자들을 눌러보자. 그리고 그 URL을 한번 확인해보자.
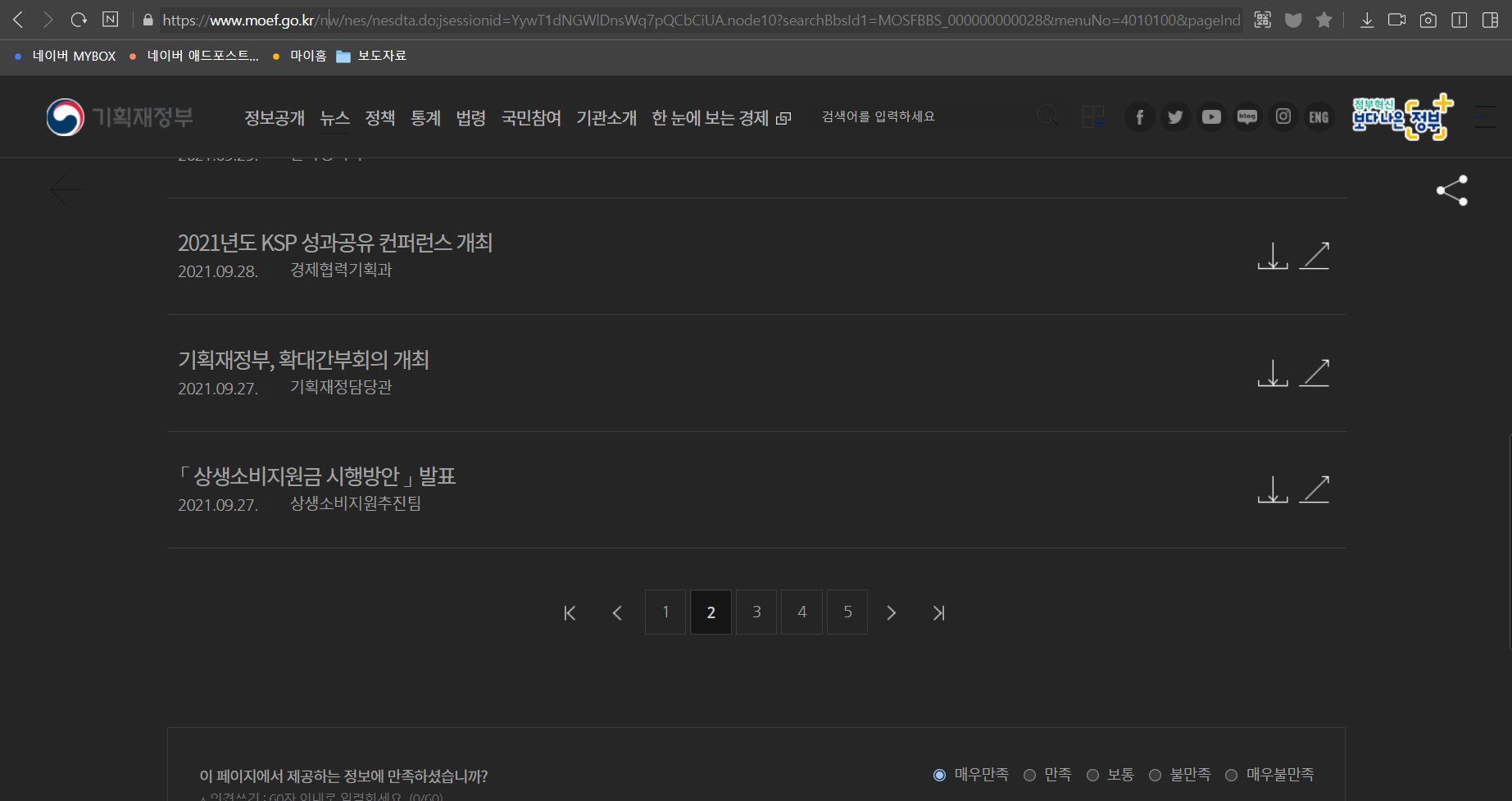
https://www.moef.go.kr/nw/nes/nesdta.do?searchBbsId1=MOSFBBS_000000000028&menuNo=4010100&pageIndex=1
https://www.moef.go.kr/nw/nes/nesdta.do?searchBbsId1=MOSFBBS_000000000028&menuNo=4010100&pageIndex=2
https://www.moef.go.kr/nw/nes/nesdta.do?searchBbsId1=MOSFBBS_000000000028&menuNo=4010100&pageIndex=3
....
https://www.moef.go.kr/nw/nes/nesdta.do?searchBbsId1=MOSFBBS_000000000028&menuNo=4010100&pageIndex=1789
복사해보면 위처럼 나오게 되는데, 잘살펴보면 규칙이 하나 있다. ~do? 이후 &로 연결된 여러 파라미터들 중 pageIndex라는 것이 1,2,3,...으로 쭉 이어지는 것을 확인할 수 있다. (참고로, 글을 쓰는 현시점에 보도자료 맨 마지막페이지는 1789인데, 그게 맨 마지막에 있는 링크임을 확인할 수 있다.) 따라서, 해당 pageIndex에 대한 변화를 주는 것만으로도 해당 페이지에 대한 요청을 보낼 수 있다. 그렇다면, 이전에 사용했던 코드를 먼저 가져와서 참고하자.
import requests
from bs4 import BeautifulSoup
url = "http://www.moef.go.kr/nw/nes/nesdta.do?bbsId=MOSFBBS_000000000028&menuNo=4010100&pageIndex=1"
req = requests.get(url)
soup = BeautifulSoup(req, "html.parser")
soup.find_all('h3')
tag가 'h3'인 것은 이전 글에서 간단히 찾아봤으니 (물론 그때는 태그를 이용한 find_all을 사용하기 보다는 selector를 활용했지만), find_all을 통해 태그를 찾아준다면 위와 같이 리스트를 반환한다. 여기엔 태그가 여기저기 붙어있으니 좀 더 깔끔한 내용을 출력하기 위해서는 아래와 같이 적용해주면 된다.
for item in soup.find_all('h3'):
print(item.text)
그럼 여기서 더 나아가서, 페이지별로 수집하기 위해서는 어떻게 하면될까? 앞서서도 설명했지만 pageIndex만 수정해주면 되는데, 여러가지 방법이 있지만 가장 간단한 방법으로 (5페이지만 가져오도록 하기 위한) 코드는 아래와 같이 작성하면 된다. 그리고 잘 나오는 것을 확인할 수 있다.
import requests
from bs4 import BeautifulSoup
# 원하는 태그의 내용을 담을 리스트(item_list)와 pageIndex를 비운 url 준비하기
item_list = []
url = "http://www.moef.go.kr/nw/nes/nesdta.do?bbsId=MOSFBBS_000000000028&menuNo=4010100&pageIndex="
# 보도자료 페이지별 웹사이트 요청해서 태그를 찾고, 그것을 리스트에 연장하기
for ind in range(1,6):
req = requests.get(url+str(ind)).text
soup = BeautifulSoup(req, "html.parser")
item_list.extend(soup.find_all('h3'))
# 이쁘게 출력하기
for item in item_list:
print(item.text)
Version
Python = v.3.8 (64 bit)
requests = v.2.26.0
Beautifulsoup = v.4.9.0
'Python > Data Prep' 카테고리의 다른 글
| Selenium 을 활용한 Element 찾기 (find_element, By) | Python, Web Scraping, Web Crawling, 자동화 (0) | 2022.08.09 |
|---|---|
| Selenium을 활용한 지자체 선거 당선인 데이터 가져오기 | Web Scraping (0) | 2021.10.16 |
| [Data Prep] 제멋대로인 주소(광역지자체명) 표준화하기 (0) | 2021.08.15 |
| 금감원 XML 파일(corp_code) python으로 읽어내기 (1) | 2020.03.14 |
| [Data Prep] 파이썬을 활용한 공공데이터API 접근하기_미세먼지 통계 | BeautifulSoup, Open API (0) | 2020.03.04 |