크루스칼 알고리즘은 최소 비용으로 모든 노드를 연결하기 위해 사용하는 알고리즘 입니다. 이는 '최소 비용 신장 트리'를 찾는다고 표현하기도 합니다. 사실 구글링을 조금만 해도 설명이 잘된 글이 많아 남들처럼 세세하게 그림을 그리면서 설명하지는 않고, 제가 이해한데로 종합하고자 합니다.
우선, 알고리즘을 설명하기에 앞서 몇 가지 단어의 개념을 짚고 넘어가고자 합니다.
간선: 노드끼리 연결한 그래프에서 선에 해당
사이클: 노드끼리 연결한 그래프가 서로 연결되어 루프를 형성하는 경우
여기서 최소 비용 신장 트리에서는 사이클이 발생하면 안됩니다. 간단히 생각하더라도, 사이클이 있으면 거리가 멀어지게 되기 때문에 최소 비용이 아니기 때문입니다. 크루스칼 알고리즘의 순서는 아래처럼 흘러갑니다.
1. 모든 간선들을 거리를 기준으로 오름차순 정렬 수행
2. 정렬 순서에 맞게 그래프에 포함
3. 포함시키기 전 사이클 테이블을 확인
4. 사이클을 형성하는 경우 간선을 포함하지 않음
- 여기서 사이클 형성 여부를 체크할 때는 Union-Find 알고리즘을 적용
import sys
# Union-Find 와 동일
N = int(sys.stdin.readline().rstrip()) # 노드 수
e = int(sys.stdin.readline().rstrip())
parent = [0] * (N+1) # 부모 행 초기화
# 부모 행 자기자신으로 설정
for n in range(1, N+1):
parent[n] = n
def find(parent, x):
if parent[x] == x:
return x
parent[x] = find(parent, parent[x])
return parent[x]
def union(parent, a, b):
a = find(parent, a)
b = find(parent, b)
if a < b:
parent[b] =a
else:
parent[a] = b
# 간선 정보
edges = []
total_cost = 0
for _ in range(e):
a, b, cost = map(int, sys.stdin.readline().split())
edges.append((cost, a, b))
# 거리 기준으로 오름차순 정렬
edges.sort()
for i in range(e):
cost, a, b = edges[i]
if (find(parent, a) != find(parent, b)):
union(parent, a, b)
total_cost += cost
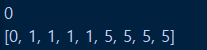
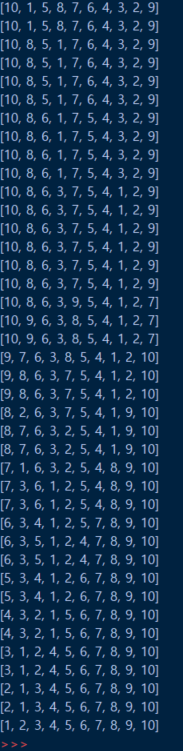
print(total_cost)입력값을 아래 링크와 동일하게 사진과 같이 넣으면 total_cost가 123으로 동일하게 나오는 것을 확인할 수 있습니다.

참고자료
1. 안경잡이 개발자, "18. 크루스칼 알고리즘(Kruskal Alogrithm)",
https://m.blog.naver.com/PostView.naver?blogId=ndb796&logNo=221230994142&navType=by
18. 크루스칼 알고리즘(Kruskal Algorithm)
이번 시간에 다루어 볼 내용은 바로 크루스칼 알고리즘입니다. 크루스칼 알고리즘은 가장 적은 비용으로 모...
blog.naver.com
2. Wikipedia, https://ko.wikipedia.org/wiki/%ED%81%AC%EB%9F%AC%EC%8A%A4%EC%BB%AC_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
크러스컬 알고리즘 - 위키백과, 우리 모두의 백과사전
컴퓨터 과학에서, 크러스컬 알고리즘(영어: Kruskal’s algorithm)은 최소 비용 신장 부분 트리를 찾는 알고리즘이다. 변의 개수를 E {\displaystyle E} , 꼭짓점의 개수를 V {\displaystyle V} 라고 하면 이 알고
ko.wikipedia.org
'Python > CS' 카테고리의 다른 글
| [알고리즘] 파이썬으로 순회(Traversal) 구현하기 | Python, Algorithm, Traversal, Binary Tree (0) | 2022.02.17 |
|---|---|
| [자료구조] 파이썬으로 이진트리 구현하기 (0) | 2022.02.14 |
| [알고리즘] 파이썬으로 '합집합 찾기' 구현하기 | Python, Union Find (0) | 2022.02.07 |
| [알고리즘] 파이썬으로 깊이 우선 탐색 구현하기 | Python, Algorithm, DFS (0) | 2022.01.03 |
| [알고리즘] 파이썬으로 너비 우선 탐색 구현하기 | Python, BFS (0) | 2021.12.27 |