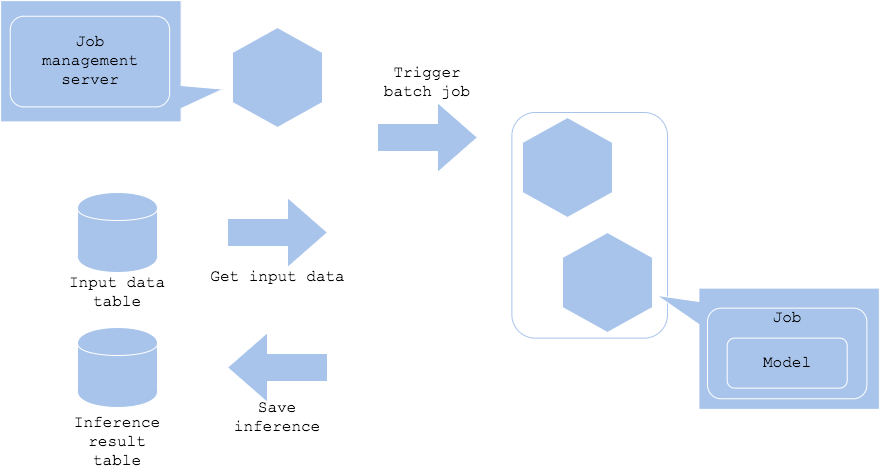
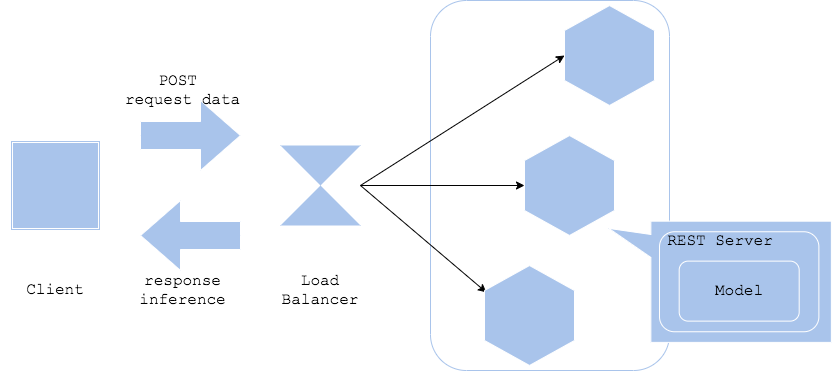
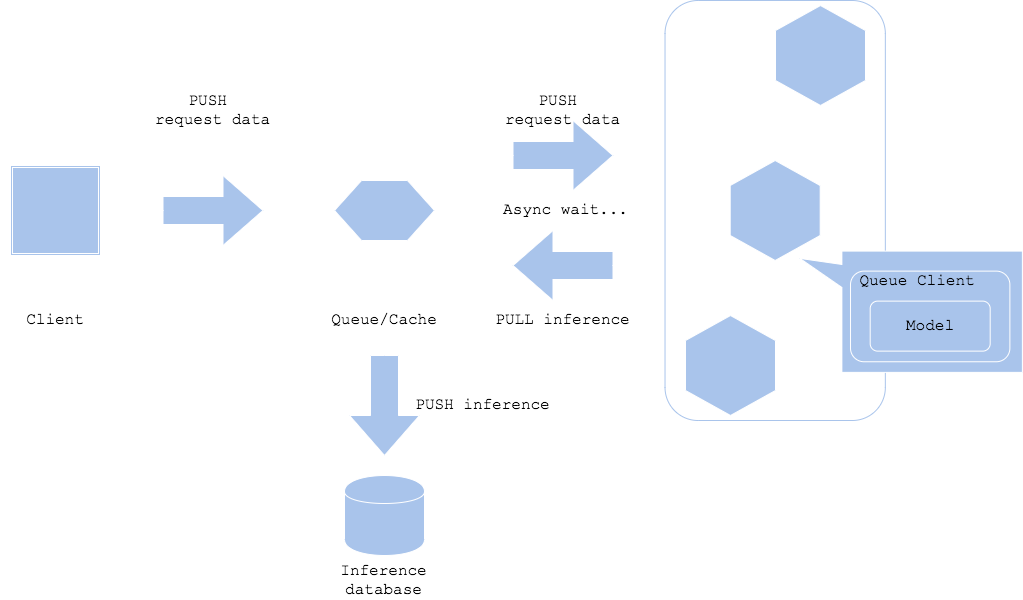
Computing Service
연산을 수행하는 가상의 컴퓨터로 일반적으로는 서버를 말합니다. CPU, 메모리, GPU 등을 선택합니다. 당연하겠지만, 이들의 성능이 좋아질수록 과금되는 금액이 비쌉니다. 클라우드 서비스를 이용하기 위해서는 인스턴스를 생성 후 인스턴스에 들어가서 사용이 가능합니다. 여기서 인스턴스란 클라우드 서비스에서 제공하는 서버 리소스를 말합니다. [1]
- 예시 : AWS(EC2), Google Cloud (Compute Engine)
Serverless Computing
컴퓨팅 서비스와 유사하지만, 서버 관리를 클라우드 쪽에서 진행하는 것을 말합니다. 컴퓨팅 서비스는 서버에서 오류가 나면 이용자가 디버깅을 해야하지만, 서버리스는 그럴 필요가 없습니다. 사용하기 위해서는 코드를 클라우드에 제출하면, 그 코드를 가지고 서버를 실행합니다. 요청 부하에 따라 자동으로 확장되는 기능인 Auto Scaling 옵션도 있습니다.
- 예시 : AWS (Lambda), Google Gloud (Cloud Function)
Stateless Computing
컨테이너 기반으로 서버를 실행하는 구조를 말합니다. 여기서 Stateless란 컨테이너 외부(DB, 클라우드 저장소 등)에 데이터를 저장하고, 컨테이너는 그 데이터로 동작하는 것입니다. 서버리스와 유사하게 요청 부하에 따라 자동으로 확장되는 기능인 Auto Scaling 옵션도 있습니다.
- 예시 : AWS (ECS), Google Gloud (Cloud Run)
Object Storage
다양한 형태의 데이터를 저장할 수 있는 저장소입니다. 이미지, csv 어떤 형태든 저장이 가능하며, API를 사용해 데이터에 접근합니다.
- 예시 : AWS (S3), Google Gloud (Cloud Storage
Database
클라우드 서비스에서 제공하는 데이터 저장소입니다. 보통 웹이나 앱 서비스에 연결해서 사용됩니다.
- 예시 : AWS (RDS), Google Gloud (Cloud SQL)
Data Warehouse
데이터 웨어하우스는 데이터 저장소라는 점에서 동일하지만, 데이터 분석이라는 목적이 분명합니다. 데이터 분석에 특화된 데이터베이스로 분석을 위해서 DB, Object Storage의 데이터를 이동시킵니다.
- 예시 : AWS (Redshift), Google Gloud (BigQuery)
AI Platform
머신러닝, 딥러닝 등 AI에 대한 수요가 늘어나면서 AI 연구 및 개발 과정을 편리하게 해주는 서비스도 많아지고 있습니다. 이를 도울 수 있는 다양한 제품과 MLOps 서비스를 제공하는 것을 AI Platform이라 합니다.
- 예시 : AWS (Lambda), Google Gloud (Cloud Function)
Virtual Private Cloud (VPC)

VPC는 논리적으로 격리된 가상 네트워크입니다. 같은 네트워크이지만 보안상 이유로 분리를 했기 때문에 여러 서버를 하나의 네트워크로 묶는 개념이라고 볼 수 있습니다. VPC에서 추가적인 개념인 서브넷(subnet)은 VPC 안에서 여러 망으로 쪼개는 것으로 외부에서 접근 가능한 public subnet과 접근 불가능한 private subnet 로 구분됩니다. 라우팅 테이블은 네트워크 트래픽이 전달되는 위치를 결정합니다. [2]
참고자료
[1] https://aws.amazon.com/ko/what-is/cloud-instances/
[2] https://docs.aws.amazon.com/ko_kr/vpc/latest/userguide/what-is-amazon-vpc.html
[3] 변성윤. "[Product Serving] 클라우드 서비스". boostcamp AI Tech.
'Note > IT-related' 카테고리의 다른 글
| 온라인 서빙을 위한 웹에 대한 기본 지식 정리 | REST API (1) | 2024.12.12 |
|---|---|
| 머신러닝 / 딥러닝의 Product Serving과 디자인 패턴 (0) | 2024.12.10 |