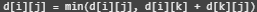PIL(Python Imaging Library)는 파이썬 환경에서 이미지를 처리할 수 있도록 도와주는 대표적인 라이브러리 중 하나입니다. 이미지 읽기, 쓰기, 변환, 조작 등이 가능하며 다양한 이미지 파일 형식을 지원하기 때문에 다양한 곳에서 사용됩니다. 이번 글에서는 기본적으로 PIL이 설치되어 있음을 가정하고, 이미지 데이터에 대한 EDA를 수행하기에 앞서 필요한 이미지 속성들을 추출하는데 집중합니다.
PIL에서 지원하고 있는 이미지 특성 추출 기능은 아래와 같습니다.
filename : 파일명
format : 파일의 형식(JPEG, PNG 등)
mode : 이미지의 색상 모드로 픽셀이 표현 방법 (L-그레이, RGB-색상, CMYK-인쇄용 등)
size : 픽셀 기준의 이미지 사이즈 (너비, 높이)로 반환
info : 파일에 포함하고 있는 메타 데이터
is_animated : 애니매이션 여부를 True / False 로 반
n_frames : 애니메이션 이미지(GIF 등)에서 총 프레임 수, 기본 이미지는 1
사진 이미지 데이터를 가져온다고 가정하고 간단하게 아래와 같이 구현할 수 있습니다.
from PIL import Image
# path는 이미지의 경로 예를 들어 ./class1/image1.jpg 형태
img = Image.open(path)
width, height = img.size
mode = img.mode
format = img.format
또한, 이미지의 주요 특징 중 하나인 색상은 파일에서 3 채널(RGB 기준)로 구현됩니다. 저는 여기서 두가지 방법을 소개하고자 합니다. 첫번째는 .split()으로 나누는 방법, 두번째는 슬라이싱으로 구현하는 방법입니다. split() 메서드는 이미지를 각 색상 채널로 분리한 후, 각 채널을 개별 이미지 객체로 반환합니다. 여기서 각 채널은 별도의 그레이 스케일 이미지로 반환됩니다. 아래는 두 방법의 코드입니다.
from PIL import Image
img = Image.open('/content/example.jpg')
r, g, b = img.split()
red1 = np.array(r)
red2 = np.array(img)[:,:,0]
print(red1)
print(red2)
이러한 여러 이미지 속성들과 이들을 조합한 데이터로 EDA에 쓸 수 있는 코드를 아래와 같이 모았습니다. 필요할 경우 함수로 구현해서 사용할 수 있습니다.
from PIL import Image
with Image.open(image_path) as img:
img = img.convert('RGB') # 이미지를 RGB 모드로 변환
width, height = img.size
img_array = np.array(img)
mean_red = np.mean(img_array[:, :, 0])
mean_green = np.mean(img_array[:, :, 1])
mean_blue = np.mean(img_array[:, :, 2])
format = image_path.split('.')[-1].upper()
image_aspect_ratio = img.width / img.height
벨만-포드 알고리즘(Bellman-Ford algorithm)은 특정 출발 노드에서 다른 모든 노드까지의 최단 경로를 구하는 알고리즘입니다. 특징 중 하나는 엣지의 가중치가 음수여도 활용이 가능하다는 점이며, 이러한 음수 사이클의 존재 여부를 판별하는 것이 벨만-포드 알고리즘의 중요한 것 중 하나 입니다. 벨만-포드 알고리즘의 구체적인 작동 원리는 아래와 같이 구현할 수 있습니다.
1단계 : 초기화
벨만-포드 알고리즘은 엣지를 중심으로 동작하기 때문에 엣지 리스트를 구현합니다. 이전 다른 그래프 경우와 유사하게, 거리 리스트에 대해서는 출발 노드는 0, 나머지 노드는 무한대로 초기화도 수행합니다.
graph = [] # 에지 리스트
for _ in range(num_edge):
u, v, w = map(int, input().split())
graph.append((u, v, w))
D = [float('inf')] * n # 노드의 개수
D[start] = 0
2단계 : 거리 리스트 업데이트
모든 에지를 확인해 총 (n-1)번 거리 리스트를 업데이트합니다. (D[e] = D[s] + w) 업데이트를 수행하기 위한 AND 조건은 다음과 같습니다.
D[s] != inf
D[e] > D[s] + w
for _ in range(n-1):
for s, e, w in graph:
if D[s] != float('inf') and D[e] > D[s] + w:
D[e] = D[s] + w
3단계 : 음수 사이클 탐지
에지 리스트에 있는 모든 에지에 대해서 위에서 언급한 조건을 만족하는 경우에는 음수 사이클이 존재하는 것을 알 수 있습니다.
for s, e, w in graph:
if D[s] != float('inf') and D[e] > D[s] + w:
return None
return D
최종 코드
위에서 설명한 단계에 따른 최종 코드는 아래와 같이 구현할 수 있습니다.
graph = []
for _ in range(num_edge):
u, v, w = map(int, input().split())
graph.append((u, v, w))
def bellman_ford(start, graph):
D = [float('inf')] * n # 노드의 개수
D[start] = 0
for _ in range(n-1):
for s, e, w in graph:
if D[s] != float('inf') and D[e] > D[s] + w:
D[e] = D[s] + w
for s, e, w in graph:
if D[s] != float('inf') and D[e] > D[s] + w:
return None
return D
플로이드-워셜(Floyd-Warshall) 알고리즘은 특정 노드가 아닌 모든 노드에서 최단 경로를 찾을 수 있는 알고리즘 입니다. 그래프의 모든 노드에서 다른 노드까지 최단 경로를 계산하는 것으로 (특정 시점에 국한된 것이 아닌) 각 노드에서 다른 노드까지 최단 경로의 행렬을 반환합니다.
3개의 for문으로 비교적 쉽게 구할 수 있지만, 그만큼 많은 연산을 요구합니다. 코딩 테스트 문제에서 만약 나온다고 하면, 비교적 노드 범위 개수가 적게 주어질 경우 이 알고리즘을 적용해보는 것도 방법이 될 듯 합니다.
1 단계 : 초기화
D[s][e]는 노드 s에서 e까지 가는 최단 거리를 저장하는 거리 리스트 입니다. 먼저 이 리스트를 출발 ~ 도착 지점이 같은 경우 (s =e) 0, 다른 칸을 무한대의 값으로 초기화 합니다.
V = len(graph) # 노드 개수
D = [[float('inf') * (V+1) for _ in range(V+1)]]
# 자기 자신에게 가는 거리 = 0
for i in range(1, V+1):
D[i][i] = 0
2 단계 : 그래프 데이터 저장
출발 노드[s]와 도착 노드[e], 가중치 w라고 했을 때 D[s][e] = w 로 저장을 진행합니다. 코드에서는 graph를 따로 입력 받은 것을 가정하기 때문에 아래와 같이 코드를 입력할 수 있습니다.
# 그래프 데이터 저장
for i in range(V):
for j in range(V):
D[i][j] = graph[i][j]
3 단계 : 점화식
플로이드-워셜 알고리즘은 아래 점화식을 진행하면 됩니다.
위 점화식은 아래와 같이 구현 가능합니다.
# 점화식에 따라 업데이트
for k in range(1, V+1):
for s in range(1, V+1):
for e in range(1, V+1):
if D[s][e] > (D[s][k] + D[k][e]):
D[s][e] = (D[s][k] + D[k][e])
최종 코드
위 단계를 모두 종합하면 아래와 같이 요약될 수 있습니다. 아래 코드에서 반환하는 D 행렬은 출발 ~ 도착 노드에서 최단 거리를 구할 수 있습니다. 예를 들어, 1부터 5까지 가는 최단 거리는 D[1][5]를 통해 구할 수 있습니다.
def floyd_warshall(graph):
V = len(graph) # 노드 개수
D = [[float('inf') * (V+1) for _ in range(V+1)]]
for i in range(1, V+1):
D[i][i] = 0
for i in range(V):
for j in range(V):
D[i][j] = graph[i][j]
for k in range(1, V+1):
for s in range(1, V+1):
for e in range(1, V+1):
if D[s][e] > (D[s][k] + D[k][e]):
D[s][e] = (D[s][k] + D[k][e])
return D
다익스트라(Dijkstra) 알고리즘은 가중치가 있는 그래프에서 노드 간 최단 경로를 찾는 알고리즘 입니다. 이러한 특성을 이용해서 네트워크 경로 탐색, 그래프 기반 최적화, GPS 등 문제에서 사용이 가능합니다.
알고리즘 동작 원리
다익스트라 알고리즘은 다음 5단계로 구성할 수 있습니다.
주어진 그래프를 인접 리스트를 구현 합니다.
출발 노드를 설정(0)하고, 이외의 다른 노드들은 무한대로 초기화합니다.
방문하지 않은 노드 중에서 최단 거리를 갖는 노드를 선택합니다. 선택된 노드는 방문 처리 합니다. (맨 처음에는 출발 노드에서 시작합니다)
방문 처리한 노드를 지나서 다른 노드를 탐색하면서 더 짧은 경로가 있으면 다른 노드를 업데이트 합니다.
3~4 과정을 모든 노드를 방문할 때까지 반복합니다.
1단계 : 인접 리스트 구현
인접 리스트는 다른 그래프 문제에서도 많이 사용하는만큼 동일하게 구현하면 됩니다. 다만, 다익스트라의 경우 엣지의 가중치가 존재하므로 3개의 입력값을 받는다는 사실만 기억하면 됩니다. 알고리즘 테스트에 대비하기 위한 형태로 구현하면 다음과 같습니다.
graph = [[] for _ in range(num_node)]
for _ in range(num_edge):
s, e, w = map(int, input().split())
graph[s].append((e, w))
2단계 : 초기화
다음으로는 거리에 대한 초기화를 진행합니다. 출발 노드는 0, 이외의 노드는 무한으로 초기화합니다. 이 때 시작점도 (거리, 노드) 형태로 같이 설정합니다.
distances = {node: float('inf') for node in graph}
distances[start] = 0
pq = [(0, start)] # 시작점 설정
3단계 : 노드 방문 여부 체크
먼저 방문하지 않은 노드를 찾습니다. 다익스트라 알고리즘에서는 현재 노드에서 거리가 거리 리스트에 있는 값보다 크면, 이미 처리된 노드임을 알 수 있습니다. (왜냐하면 그전까지는 무한의 값이기 때문에) 이미 방문한 노드이면 continue로 다음 노드를 꺼내옵니다.
current_distance, current_node = heapq.heappop(pq)
# 이미 처리된 노드는 무시
if current_distance > distances[current_node]:
continue
4단계 : 최단 경로 업데이트
선택된 노드에서 다른 노드에 연결된 경로를 확인하면서, 더 짧은 경로가 있으면 해당 경로로 업데이트 합니다. 더 짧은지 여부는 (선택한 노드의 거리 리스트 값 + 에지 가중치)와 (연결된 노드의 거리 리스트 값)을 비교해서 업데이트를 수행 합니다.
# 이웃 노드 확인
for neighbor, weight in graph[current_node].items():
distance = current_distance + weight
# 더 짧은 경로 비교
if distance < distances[neighbor]:
distances[neighbor] = distance # 업데이트
heapq.heappush(pq, (distance, neighbor))
전체 코드
앞 과정 3~4단계를 반복하면서 모든 노드에 대해 처리될 때까지 수행합니다. 이는 우선순위 큐가 빌 때까지 수행되는 while 문으로 구현 가능합니다. 위 단계까지 포함하여 구현된 코드는 아래와 같습니다.
import heapq
graph = [[] for _ in range(num_node)]
for _ in range(num_edge):
s, e, w = map(int, input().split())
graph[s].append((e, w))
def dijkstra(graph, start):
distances = {node: float('inf') for node in graph}
distances[start] = 0
pq = [(0, start)]
while pq:
current_distance, current_node = heapq.heappop(pq)
if current_distance > distances[current_node]:
continue
for neighbor, weight in graph[current_node].items():
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(pq, (distance, neighbor))
return distances
딥러닝을 위해 데이터를 불러오거나 전처리하는 방법을 매번 작성하는 것은 비효율적이고 반복적인 작업이 될 수 있습니다. PyTorch에서는 torch.utils.data를 통해 다양한 클래스를 제공하고 있으며, 제공된 클래스를 적절히 활용하면 효율적이고 유연한 데이터 파이프라인을 구축할 수 있습니다.
Dataset
torch.utils.data.Dataset은 키 -> 데이터 샘플로 매핑되는 모든 데이터셋을 표현하기 위해 Dataset을 상속받아 사용합니다. 데이터를 초기화하는 __init__ 메서드, 데이터 크기를 반환하는 __len__ 메서드, 특정 인덱스의 데이터 샘플을 반환할 수 있도록 하는 __getitems__ 메서드를 구현할 수 있습니다.
import torch
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, data, labels):
self.data = data
self.labels = labels
def __len__(self): # 데이터셋의 총 샘플 수를 반환
return len(self.data)
def __getitem__(self, idx): # 주어진 인덱스에서 데이터와 레이블을 반환
sample = self.data[idx]
label = self.labels[idx]
return sample, label
위 예시에 대해 아래와 같이 생성해보고, 결과를 출력해보겠습니다. 먼저 예제로 사용할 데이터셋을 생성하고 가장 첫번째에 있을 데이터를 출력해보겠습니다.
data = torch.randn(100, 3)
labels = torch.randint(0, 2, (100,))
그렇다면 만들어본 클래스가 잘 작동되는지 출력해보겠습니다. __len__는 len()함수를 통해 확인하고, __getitem__은 [index]를 통해 접근해보겠습니다. 출력 결과를 보니, 문제가 없이 잘 구현된 것을 확인했습니다.
torch.utils.data.DataLoader는 데이터를 배치(batch: 데이터를 건마다 처리하는 것이 아닌, 한 번에 처리되는 데이터의 묶음) 단위로 처리하고 병렬작업을 지원해 속도를 높입니다. 앞에서 만든 Dataset의 인스턴스를 감싸 배치 크기에 맞춰 나눠주고, 특정 순서에 의존하지 않도록 섞어주는 기능(shuffle : 훈련에서는 True / 테스트는 False)도 제공합니다. 또한, 필요할 경우 여러 스레드를 사용해 데이터를 병렬로 로드할 수 있도록 기능(num_workers)도 제공하고 있습니다. 외에도 다양하게 사용할 수 있으니 아래 링크를 통해 학습하면 좋습니다.
머신러닝에서 학습을 위해 필요한 과정 중 하나로 역전파를 통해 손실함수의 그래디언트를 계산합니다. 이렇게 계산한 값을 활용해 경사 하강법 단계에서 파라미터를 수정하게 되죠. [1]
그런데 여러개의 연산을 쌓아서 만들어진 인공신경망(네트워크)에서 그래디언트가 작아지는 경우가 있습니다. 이렇게 값이 작아진다면 수렴이 되지 않아 원하는 결과를 얻지 못하게 되는데, 이러한 경우를 '그래디언트 소실(vanishing gradient)'이라 합니다. 그와 반대되는 현상으로 그래디언트가 커지면서 파라미터가 수렴하지 않고 발산하게 되는 '그래디언트 폭주(exploding gradient)'도 있습니다. [2]
이렇게 그래디언트가 소멸하거나 폭주하게 되면, 신경망 훈련이 어려워지게 됩니다. 이를 해결하기 위해 다양한 방법들이 연구되었는데, 여기서는 두가지만 우선 소개합니다.
2. 활성화 함수
활성화 함수는 인공 신경망의 각 요소들에서 함수를 언제 활성화할 것인지에 대해 결정하는 함수를 말합니다. 활성화 함수 사용가능한 것들은 시그모이드 함수(로지스틱), 하이퍼볼릭 탄젠트 함수, ReLU (Rectified Linear Unit) 함수가 있습니다. 종류는 다양하지만, 활성화 함수를 잘못 선택할 경우 그래디언트 소실이나 폭주 현상이 일어날 수 있어 주의가 필요합니다.
여러 연구를 거치면서 ReLU 함수가 특정 양수로 수렴하지 않는 것이 밝혀졌고, 지수함수를 사용하는 다른 함수에 비해 1차 함수이기 때문에 연산도 빠릅니다. 여러 장점이 있지만, 음수 영역에서 0을 출력하는 Dead ReLU 문제를 발생하기 때문에 음수영역에 약간의 기울기(예 : 0.01)를 주는 Leaky ReLU, 음수 영역에서 지수함수를 포함한 ELU(Exponential Linear Unit)을 통해 해결이 가능합니다. [1]
파이토치에선 nn 모듈에서 다양한 활성화함수를 활용할 수 있습니다.
import torch.nn as nn
relu = nn.ReLU()
leaky_relu = nn.LeakyReLU(negative_slope = 0.01)
elu = nn.ELU(alpha = 1.1)
3. 가중치 초기화
이전 머신러닝 사이클에서 모델 기반 학습의 두번째 단계로 '무작위로 파라미터 설정'(여기서 부터는 '초기화')을 얘기한 바 있습니다. [1] 다른 단계들은 한번씩 논의가 됐지만, 이 단계에 대해서는 따로 다룬 적이 없지만 올바른 학습을 위해서는 더 나은 초기화가 이뤄져야 합니다.
만약 초기화 값을 np.random.randn 처럼 정규분포에 맞춰서 데이터를 생성하게 되면 어떻게 될까요? 아래와 같이 값들이 0과 1에 치우쳐서 분포하게 됩니다. 이렇게 될 경우 활성화 함수(예를 들어, 시그모이드 함수)의 값이 0이 되기 때문에 기울기가 없어지는 문제가 생깁니다. 이를 그래디언트 소실(vanishing gradient) 문제라고 합니다.
활성화 값 분포 [3]
그렇다면, 그래디언트 소실 문제를 해결하려면 어떻게 해야 할까요? 대표적으로 많이 사용하는 방법은 Xavier 초기화, He 초기화(또는 Kaming 초기화. Kaming He의 이름.)를 활용하는 것 입니다. 파이토치에서는 torch.nn.init을 통해 지원하고 있습니다.
극좌표계(polar coordinate system)는 평면 위의 위치를 각도와 거리 성분으로 표현하는 2차원 좌표계입니다. 일반적으로 사용하는 x/y축으로 표현되는 데카르트 좌표계에서는 표현하기 어려운 것들을 극좌표계로 표현하면 쉽게 표현되는 경우들이 있어서 종종 사용됩니다. [1] 예를 들어, 레이더 , 바람의 풍향과 풍속과 같은 것을 표현하는데 많이 사용했고, 최근에는 여러 요소들을 비교가 필요한 게임 / 모델 비교 등에도 활용이 가능합니다.
극좌표계는 시각화된 차트가 놓일 틀일 뿐, 실제로 그림을 넣을 수 있습니다. 일반적으로 사용하는 데카르트 좌표계가 아니다보니, 심미적으로 괜찮은 시각화가 될 수 있지만 때로는 명확한 데이터 비교가 어려울 수 있으니 충분히 고민이 필요합니다.
# 설정
N = 6
r = np.random.rand(N)
theta = np.linspace(0, 2*np.pi, N, endpoint=False)
# 막대 그래프 그리기
fig = plt.figure()
ax = fig.add_subplot(111, projection='polar')
ax.bar(theta, r, width=0.5, alpha=0.5)
plt.show()
# 실습 3. 극좌표계에 선그래프 넣기
극좌표계는 다른 그래프인 선 그래프를 넣어보겠습니다. 아르키메데스 나선이라 불리는 비교적 간단한 나선을 입력하면 아래와 같이 그림이 나오게 됩니다. [2]
import matplotlib.pyplot as plt
import numpy as np
r = np.arange(0, 2, 0.01)
theta = 2 * np.pi * r
fig, ax = plt.subplots(subplot_kw={'projection': 'polar'})
ax.plot(theta, r)
ax.set_rmax(2)
ax.set_rticks([0.5, 1, 1.5, 2]) # Less radial ticks
ax.set_rlabel_position(-22.5) # Move radial labels away from plotted line
ax.grid(True)
ax.set_title("A line plot on a polar axis", va='bottom')
plt.show()
# 실습 4. 축구 선수 능력치 시각화
레이더 차트(Radar chart)는 극좌표계에 값을 채워가는 방식으로 그래프를 그리는 것입니다. 실제로 게임에서 많이 활용되는 차트 형태로 데이터를 한번에 보기에 좋은 차트 입니다. 대표적으로 사용하는 게임인 축구 게임으로 레이더 차트를 시각화를 해보겠습니다. 아래 그림은 축구 게임의 손흥민 선수의 능력치입니다. 해당 값을 바탕으로 레이더 차트를 만들어 보겠습니다.
FC 24 손흥민 선수 능력치 [3]
import matplotlib.pyplot as plt
import numpy as np
stats = ["PAC", "SHO", "PAS", "DRI", "DEF", "PHY"]
theta = np.linspace(0, 2*np.pi, 6, endpoint=False)
son = np.array([87, 88, 80, 84, 42, 70])
# 끝의 점끼리 연결
son = son.tolist() + [son[0]]
theta = theta.tolist() + [theta[0]]
fig = plt.figure()
ax = fig.add_subplot(111, projection='polar')
ax.plot(theta, son, color='forestgreen')
ax.fill(theta, son, alpha=0.3, color='forestgreen')
ax.set_thetagrids([n*60 for n in range(6)], stats)
ax.set_rmax(100)
plt.show()
시각화를 진행하다보면 데이터로 그려진 그래프만으로는 부족한 경우가 있습니다. 아래와 같은 사례가 있을 수 있죠.
특정 값 (최대, 최소 등)에 대한 지칭이 필요하다.
어느 한점으로부터 얼마나 멀리 떨어져 있는지 시각적으로 바로 알아차리게 하고 싶다.
특정한 구간을 표시하고 싶다.
이번 글에서는 시각화 효과를 높이기 위해 다양한 도구들에 대해 살펴보려고 합니다.
다양한 그리드 생성하기
matplotlib에서는 pyplot.grid를 통해 그리드를 생성할 수 있습니다. 하지만, 그리드의 사전적 의미처럼 격자 형태의 비교적 단순한 형태의 그리드만 생성할 수 있어 유연성에 있어서는 조금 아쉽습니다. 대신에 matplotlib에서 제공하고 있는 다양한 차트 시각화 도구를 이용해 색상, 선의 유형, 두께 등을 조절해서 조금 덜 보이도록 해서 다양한 그리드를 생성할 수 있습니다. 여기선 직선과 원 형태의 그리드의 간단한 형태를 생성해보도록 하겠습니다.
먼저, 아래와 같이 [0,1] 사이에 10개의 랜덤 데이터를 생성하겠습니다. 이 데이터를 바탕으로 다양한 보조선을 그려보도록 하겠습니다.
import numpy as np
import matplotlib.pyplot as plt
x = np.random.uniform(0, 1, size=10)
y = np.random.uniform(0, 1, size=10)
np.random.seed(1)
# 실습 1. x + y = c 그리기
x + y = c (c는 바뀜)직선을 그리는 방법은 1차 함수의 x, y 절편을 변화시키면서 그 값을 변화시켜주면 됩니다. 주된 그래프가 아니기 때문에 잘 보이지 않게 점선(--), 회색, 투명도를 설정하고 그려줄 수 있습니다.
fig, ax = plt.subplots()
ax.scatter(x, y)
# Grid : x + y = c
x_start = np.linspace(0, 2.2, 12, endpoint=True) # 절편 값 변화에 따라 나눔
for xs in x_start:
ax.plot([xs, 0], [0, xs], linestyle='--', color='gray', alpha=0.5, linewidth=1)
ax.set_title(r"Grid ($x+y=c$)", fontsize=15,va= 'center', fontweight='semibold')
ax.set_xlim(0, 1.1)
ax.set_ylim(0, 1.1)
plt.show()
# 실습 2. y = cx 그리기
y = cx (c는 바뀜) 직선은 위와 다르게 기울기가 변화하는 직선입니다. 이를 그리는 방법은 기울기의 변화를 원하는 방식으로 변화를 주면서 직선을 그려주면 됩니다. 메인 그래프가 아니라 그리드이기 때문에 잘 보이지 않게 점선(--), 회색, 투명도를 설정하고 그려줄 수 있습니다.
특정 점에서 얼마나 떨어져 있는지 살펴보기 위해선 원형 그리드가 효과적입니다. 실제로 (유클리드 공간에서) 원의 정의가 같은 거리에 있는 점들의 집합이기 때문에 정확한 활용이죠. 여기선 x[2], y[2] 값을 중심으로 얼마나 떨어져 있는지 살펴보는 코드는 아래와 같습니다. (그림을 보면 조금 이상하긴 하지만... 조금씩만 조정해주면 될 것 같습니다)
fig, ax= plt.subplots()
ax.scatter(x, y)
## Grid : (x-a)**2 + (y-b)**2 = r**2
a = x[2]
b = y[2]
rs = np.linspace(0.1, 0.8, 8, endpoint=True)
for r in rs:
xx = r*np.cos(np.linspace(0, 2*np.pi, 100))
yy = r*np.sin(np.linspace(0, 2*np.pi, 100))
ax.plot(xx+a, yy+b, linestyle='--', color='gray', alpha=0.5, linewidth=1)
ax.text(a+r*np.cos(np.pi/4), b-r*np.sin(np.pi/4), f'{r:.1}', color='gray')
ax.set_title(r"Grid ($(x-a)^2+(y-b)^2=c$)", fontsize=15,va= 'center', fontweight='semibold')
ax.set_xlim(0, 1.1)
ax.set_ylim(0, 1.1)
plt.show()
왼쪽으로 길어서 찌그러져 있어 보이지만.. 원(에 가까운 다각형) 맞습니다.
보조 선/면 그리기
시각화는 데이터를 보기 좋게 만드는 것입니다. 앞서 그리드 외에도 데이터를 살펴보기 좋게끔 만들기 위해 보조 선/면을 그리는 방법이 있습니다. 아래 그림은 kaggle에서 볼 수 있는 시각화 사례입니다.
면적을 활용해 효과적인 시각화 사례 : 연령대별 넷플릭스 평가 분포 [1]
pyplot에서 보조선(axhline, axvline)과 보조면(axhspan, axvspan)을 그릴 수 있는 다양한 메서드를 제공하고 있습니다.
# 실습 4. 보조 선 그리기
보조 선을 그리는 방법은 앞에서 설명한 메서드(axvline, axhline)을 사용하거나 pyplot.plot 을 사용하는 방법이 있습니다. 정답은 없고, 둘 중 편한 것을 사용하면 될 것 같습니다. 아래 코드는 두가지 모두 사용한 방법을 기재했습니다. 조금 주의할 것은 axvline, axhline에서 xmin과 xmax는 0~1 사이의 상대적인 위치를 넣어야 하기 때문에 표화가 필요합니다.
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure()
x = np.arange(20)
y = np.random.rand(20)
ax = fig.add_subplot(111)
ax.plot(x, y,
color='lightgray',
linewidth=2,)
ax.set_xlim(-1, 21)
# max
# ax.plot([-1, x[np.argmax(y)]], [np.max(y)]*2,
# linestyle='--', color='tomato')
ax.axhline(y=np.max(y), xmin=0, xmax= x[np.argmax(y)] / len(x),
linestyle='--', color='tomato')
ax.scatter(x[np.argmax(y)], np.max(y),
c='tomato',s=50, zorder=20)
# min
# ax.plot([-1, x[np.argmin(y)]], [np.min(y)]*2,
# linestyle='--', color='royalblue')
ax.axhline(y=np.min(y), xmin=0, xmax= x[np.argmin(y)] / len(x),
linestyle='--', color='royalblue')
ax.scatter(x[np.argmin(y)], np.min(y),
c='royalblue',s=50, zorder=20)
plt.show()
# 실습 5. 보조 면 그리기
보조 면의 사용은 axvspan, axhspan을 통해 사용이 가능합니다. 사용방법은 위에 보조선과 거의 유사합니다.
직사각형 막대를 이용해 데이터 값을 표현하는 대표적인 차트입니다. 범주에 따른 수치 값을 비교할 때 적합한 방법으로 많이 사용합니다. mataplotlib.pyplot에서는 .bar (일반적인 수직형 막대) / .barh (수평형 막대, 범주가 많을 때 아래로 내리면서 사용) 크게 두가지 방법으로 사용할 수 있습니다.
먼제 seaborn에 내장되어 있는 titanic 데이터를 불러와 데이터를 준비하겠습니다.
# Library
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
titanic = sns.load_dataset('titanic')
print(titanic.head())
여러 개의 그룹을 쌓아서 표시하는 누적 막대 그래프는 한꺼번에 다양한 카테고리를 살펴볼 수 있는 장점이 있습니다. 위에서 생성한 타이타닉 데이터셋에 bar로 먼저 바닥에 만들 그래프를 생성하고, 그 위에 bottom 파라미터에 바닥에 있을 데이터를 지정해 얹는 방식으로 진행합니다. 만약 barh를 사용하는 경우 lef 파라미터를 사용합니다.
전체 비율을 나타내기 위해서는 100 % 기준 누적 막대 그래프(Percentage stacked bar chart)를 활용해주는 것도 좋습니다. 전체 비율을 계산하기 위한 total 값 계산만 추가해서 만들어주면 됩니다.
# Percentage Stacked Barplot
fig, ax = plt.subplots()
group = group.sort_index(ascending=False)
total=group['male']+group['female']
ax.barh(group['male'].index, group['male']/total,
color='royalblue')
ax.barh(group['female'].index, group['female']/total,
left=group['male']/total,
color='tomato')
ax.set_xlim(0, 1)
for s in ['top', 'bottom', 'left', 'right']:
ax.spines[s].set_visible(False)
plt.show()
실습 4. 묶은 세로 막대형 (Grouped bar plot)
matplotlib으로 구현이 쉽지는 않지만, 여러 유형의 카테고리를 묶어서 같이 표현하는 방법도 가능합니다. 너비만큼 x축으로 평행이동 시키면서 막대 그래프를 지속적으로 그려주는 형태로 그려줄 수 있습니다. 아래는 matplolib에서 소개하고 있는 예시입니다. [1]
# data from https://allisonhorst.github.io/palmerpenguins/
import matplotlib.pyplot as plt
import numpy as np
species = ("Adelie", "Chinstrap", "Gentoo")
penguin_means = {
'Bill Depth': (18.35, 18.43, 14.98),
'Bill Length': (38.79, 48.83, 47.50),
'Flipper Length': (189.95, 195.82, 217.19),
}
x = np.arange(len(species)) # the label locations
width = 0.25 # the width of the bars
multiplier = 0
fig, ax = plt.subplots(layout='constrained')
for attribute, measurement in penguin_means.items():
offset = width * multiplier
rects = ax.bar(x + offset, # x축 평행 이동
measurement,
width,
label=attribute) # 레이블 지정
ax.bar_label(rects, padding=3)
multiplier += 1
# Add some text for labels, title and custom x-axis tick labels, etc.
ax.set_ylabel('Length (mm)')
ax.set_title('Penguin attributes by species')
ax.set_xticks(x + width, species)
ax.legend(loc='upper left', ncols=3)
ax.set_ylim(0, 250)
plt.show()