깊이 우선 탐색 (Depth-First Search, DFS)는 저번 BFS에 이은 탐색방법 중 하나로, 표현 그대로 깊이를 우선적으로 탐색하는 알고리즘 입니다. DFS는 맹목적 탐색 방법으로 스택이 사용되며, 여기서 '맹목적 탐색'은 정해진 순서대로 탐색하는 것을 의미합니다.
알고리즘의 순서는 다음과 같습니다.
- 스택의 최상단 노드
- 최상단 노드와 연결된 방문하지 않은 노드가 있으면, 그 노드를 스택에 넣고(push) 방문처리
- 방문하지 않은 노드가 없으면, 최상단 노드에서 제외
- 반복 수행
파이썬 코드는 다음과 같습니다.
def depth_first_search(graph, start, visit):
# 1. 알고리즘 최상단 노드 선택 (방문)
visit[start] = True
print(start, end=' ')
# 현재 노드와 연결된 다른 노드 방문
for i in graph[start]:
# 방문하지 않았으면, 재귀적으로 방문처리
if not visit[i]:
depth_first_search(graph, i, visit)
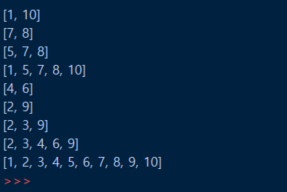
graph = [
[],
[2, 3],
[1, 3, 4, 5],
[1, 2, 6, 7],
[2, 5],
[2, 4],
[3, 7],
[3,6]
]
visit = [False] * len(graph)
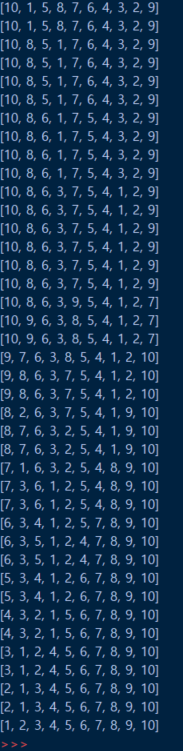
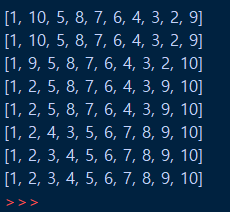
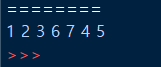
depth_first_search(graph, 1, visit)구현은 아래 사진처럼 잘 된 것을 확인할 수 있습니다.
위키피디아에서 설며앟고 있는 장단점은 다음과 같습니다.
장점:
- 현 경로상의 노드만 기억하면 되므로 저장공간의 수요가 비교적 적음
- 목표노드가 깊은 단계에 있을수록 해를 빨리 구할 수 있음
단점:
- 해가 없는 경로에 깊이 빠질 가능성
- 최단경로가 아닐 수 있음
참고자료:
https://m.blog.naver.com/ndb796/221230945092
16. 깊이 우선 탐색(DFS)
깊이 우선 탐색(Depth First Search)은 탐색을 함에 있어서 보다 깊은 것을 우선적으로 하여 탐색하는 ...
blog.naver.com
https://ko.wikipedia.org/wiki/%EA%B9%8A%EC%9D%B4_%EC%9A%B0%EC%84%A0_%ED%83%90%EC%83%89
깊이 우선 탐색 - 위키백과, 우리 모두의 백과사전
깊이 우선 탐색의 애니메이션 예시 깊이 우선 탐색( - 優先探索, 영어: depth-first search, DFS)은 맹목적 탐색방법의 하나로 탐색트리의 최근에 첨가된 노드를 선택하고, 이 노드에 적용 가능한 동작
ko.wikipedia.org
'Python > CS' 카테고리의 다른 글
| [알고리즘] 파이썬으로 크루스칼 알고리즘 구현하기 | Python, Algorithm, Kruskal (0) | 2022.02.10 |
|---|---|
| [알고리즘] 파이썬으로 '합집합 찾기' 구현하기 | Python, Union Find (0) | 2022.02.07 |
| [알고리즘] 파이썬으로 너비 우선 탐색 구현하기 | Python, BFS (0) | 2021.12.27 |
| [자료구조] 파이썬으로 큐(Queue) 사용하기 | Python (0) | 2021.12.24 |
| [자료구조] 파이썬으로 스택(Stack) 사용하기 | Python (0) | 2021.12.22 |