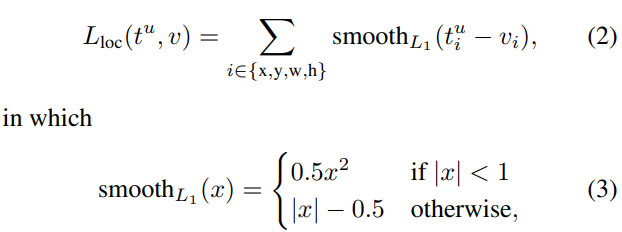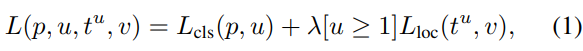도입
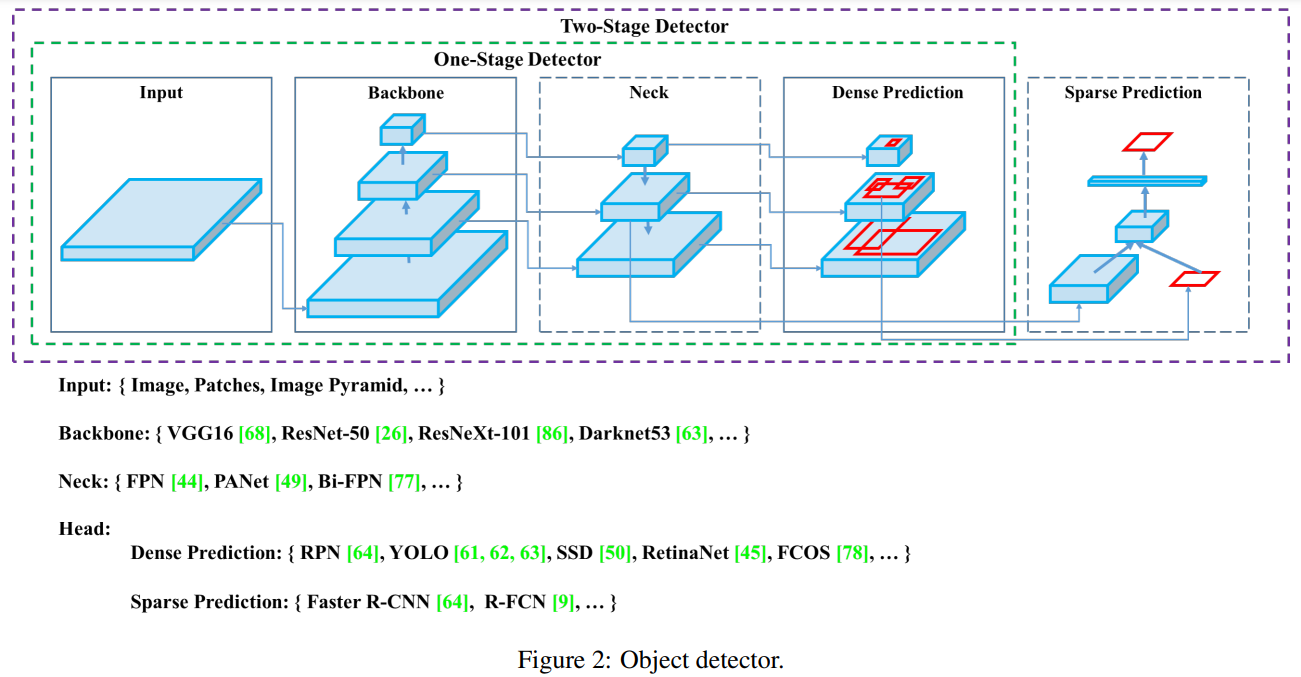
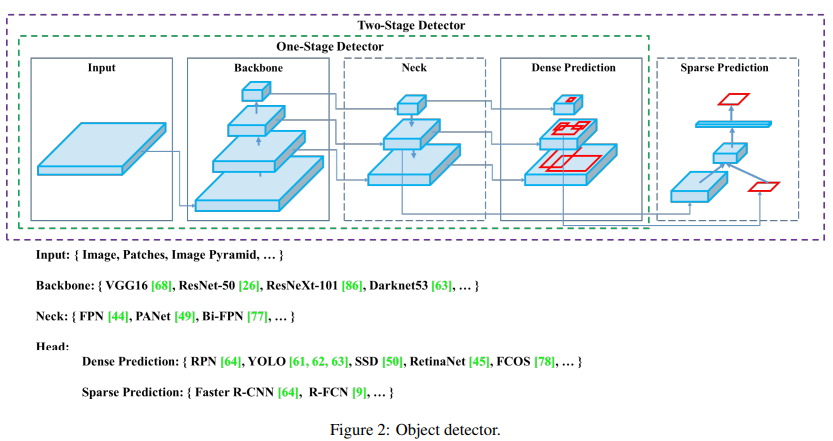
지난 2-Stage Detector 모델(2-Stage)에 이어, 이번에는 1-Stage Detector 모델(1-Stage)의 시작과 비교적 초기 모델들의 변천사를 살펴보고자 합니다. 아래 지난 글에서 다룬 것처럼 객체 탐지 모델(OD)은 후보 영역을 찾고(Localization), 후보 영역에 대한 분류(Classification) 두가지 작업이 이뤄져야 합니다. 그리고 2-Stage는 그 두가지 활동을 나눠서 수행하기 때문에 추론을 진행하는 과정에서도 속도가 느리다는 단점이 있습니다.
2024.10.10 - [노트/Computer Vision] - [OD] 2-Stage Detectors 변천사 | R-CNN 부터 Faster R-CNN 까지
[OD] 2-Stage Detectors 변천사 | R-CNN 부터 Faster R-CNN 까지
기본 개념 객체 탐지(Object Detection, OD)는 입력으로 받은 이미지에서 객체의 위치를 찾고(Localization), 그 객체가 무엇인지 분류(Classification)하는 2가지 작업이 이뤄져야 하는 보다 복합적인 작업입
seanpark11.tistory.com
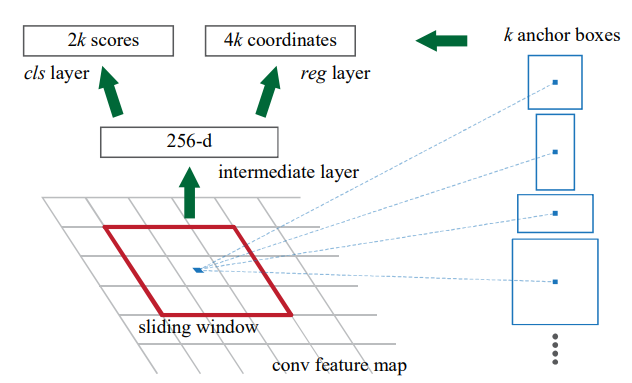
이러한 문제의식에서 출발한 1-Stage는 이 두가지 활동을 합쳐서 수행하기 때문에 속도 측면에서 강점을 보입니다. 이는 영역을 별도로 추출하지 않고, CNN Backbone 모델에서 추출한 피쳐 맵에서 바로 객체를 검출하기 때문입니다. 즉, 1-Stage는 Faster R-CNN의 RPN 처럼 Region Proposal의 과정이 없습니다.
1-Stage 모델 초기 변천사
YOLO v1
YOLO라는 모델은 You Only Look Once의 줄임말로 한번만 보면 된다는 모델의 철학을 담고 있습니다. 하나의 이미지에서 인식한다는 개념은 여러 아이디어의 조합으로 완성되었는데, 우선 YOLO v1 모델이 어떻게 이미지에서 객체를 인식하는지 과정을 살펴보면 다음과 같습니다. [2]
1) 입력 이미지를 S x S의 그리드로 분할
2) 각 그리드 셀에서 바운딩 박스와 점수(confidence score), 클래스 확률 계산
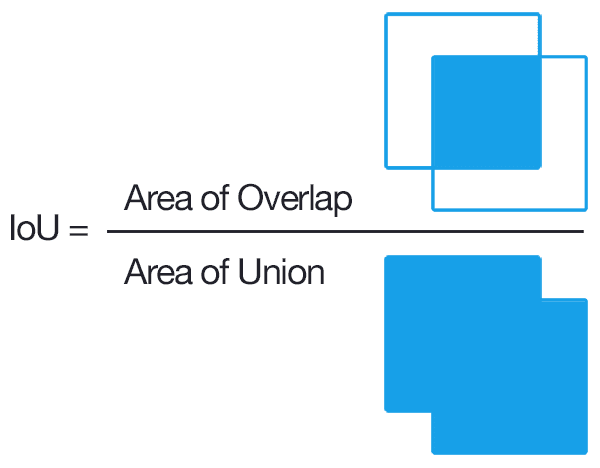
- 점수는 바운딩 박스에 객체가 없는 경우 0, 객체가 있는 경우 IoU로 정의합니다.
- 바운딩 박스에는 그리드 셀 기준 상대적인 박스 정보(x, y, w, h)와 점수를 포함해 5개 정보를 포함합니다.
- 클래스 확률은 박스에 객체가 있을 경우 해당 클래스일 확률이며, 이 확률은 클래스마다 존재합니다.
- 하나의 그리드 셀에는 (박스 개수 x 5 + 클래스 수)의 정보를 예측
3) 2) 과정을 모든 그리드 셀마다 수행
- 총 S x S 개의 그리드에 대해 2)를 수행
DarkNet
YOLO v1에서는 다른 CNN 구조를 쓴 것이 아니라, DarkNet이라는 별도의 네트워크를 제안합니다. 논문에 따르면, GoogLeNet 모델에서 영감을 받아 설계했다고 합니다. 24개의 conv 층, 2개의 fully-connected 층으로 연결하고, GoogLeNet의 inception 모듈 대신에 1x1 reduction 층을 사용합니다. 또한, OD는 fine-grained 문제이기 때문에 이를 효과적으로 수행하기 위해 2배 해상도로 높여 진행한다고 설명하고 있습니다.

입력 이미지는 DarkNet을 통해 위 객체 예측 결과 텐서를 반환합니다. 그리고 아래에 다뤄질 손실함수를 이용해 훈련을 진행합니다.
손실함수
손실함수 역시 YOLO의 철학을 반영하듯이 여러가지 손실함수를 합한 형태로 구성된 것으로 보입니다. 아래 이미지의 첫 두 항은 Localization(중심점 손실 + w & h 손실), 중간의 두 항은 Confidence score (객체가 있는 경우 + 객체가 없는 경우), 마지막은 분류 문제에 대한 손실입니다.
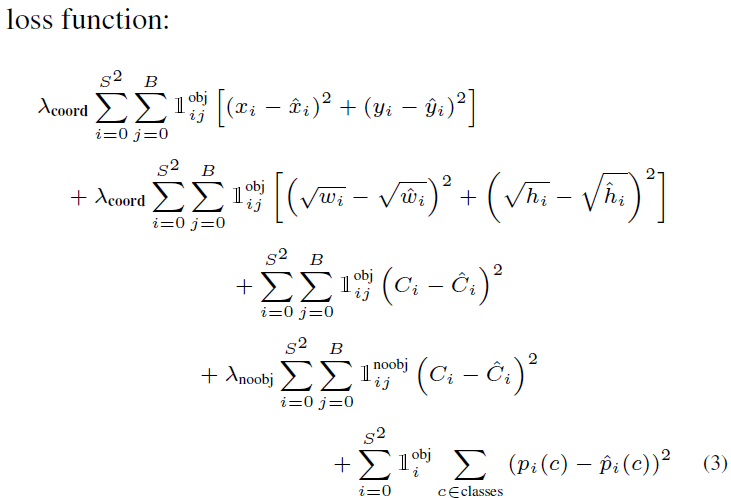
SSD
YOLO v1는 한번에 두가지 작업을 수행한다는 점에서 짧은 추론시간과 이미지 전체에서 객체 탐지가 이뤄지기에 학습되지 않은 데이터셋에서도 강점을 보이긴 했지만, 그리드 영역 단위로 수행했기 때문에 그보다 작은 객체에 대해 성능이 떨어지고 신경망의 마지막 피쳐 맵만 사용하기에 제한된 성능을 보였습니다.
Single Shot multibox Detector(SSD)는 이러한 단점들을 보완하기 위해 모든 피쳐 맵에 대해 OD를 수행합니다.
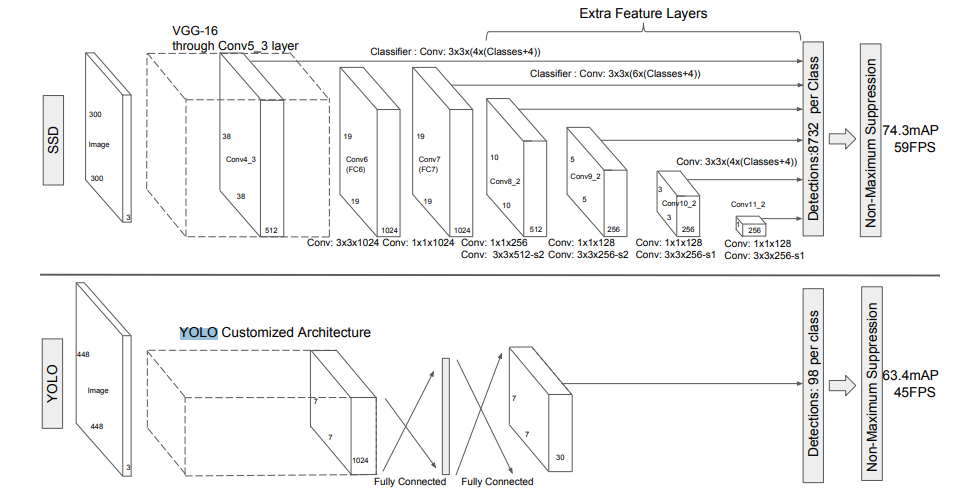
Multi-scale feature maps
SSD는 VGG16을 backbone으로 추가 conv 층을 갖고 있는 구조로 이러한 추가 층을 통해 추가적인 피쳐 맵에 대해서 예측을 진행할 수 있게 됩니다. 총 6개의 서로 다른 스케일의 피쳐 맵(각각 conv4_3, conv7, conv8_2, conv9_2, conv10_2, conv11_2에서 추출)을 가져와서 객체 탐지에 사용합니다. 큰 피쳐 맵은 작은 물체를 탐지할 수 있고, 작은 피쳐 맵은 큰 물체 탐지에 사용할 수 있습니다. 즉, 다양한 피쳐 맵을 사용하여 다양한 크기의 객체를 탐지할 수 있게 됩니다. 추가적으로 fully-connected 층 대신에 conv 층을 사용하고, 연산 속도가 빨라지는 효과도 가져오게 됩니다.
Default box
또한, Faster R-CNN에서 사용된 anchor box와 같은 default box를 이용합니다. 서로 다른 스케일과 가로세로비를 가진 박스를 사용했다는 점에서 anchor box와 유사하지만, SSD에서는 앞서 언급한 Multi-scale feature maps에 적용합니다. default box의 스케일은 아래 공식에 따라 결정되며, 가로세로비율은 {3,2,1, 1/2, 1/3}에 따라 곱한 값으로 결정됩니다.
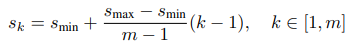
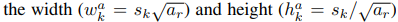
default box에서는 박스의 위치(offset)와 각 클래스에 대한 신뢰도를 예측합니다. 위치는 이전의 다른 모델과 동일하게 (x, y, w, h)로 default box마다 예측을 수행하게 되고, 클래스 + 1(배경) 까지 신뢰도 점수를 계산합니다.
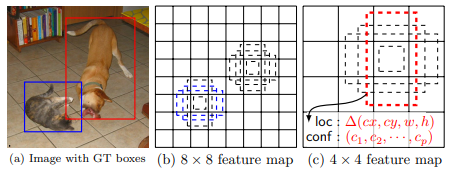
학습에서는 default box와 ground truth 사이에 IoU가 0.5 이상이면 positive, 아니면 negative로 구분합니다. 다만, 일반적으로 negative sample이 많기 때문에 높은 confidence loss를 갖는 샘플을 추가하는 hard negative mining을 통해 해결합니다. [5]
손실함수
손실함수는 Localization loss와 Confidence loss의 합으로 계산합니다. Localization은 smooth L1, Confidence는 Softmax로 계산합니다.

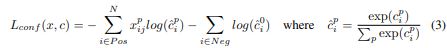
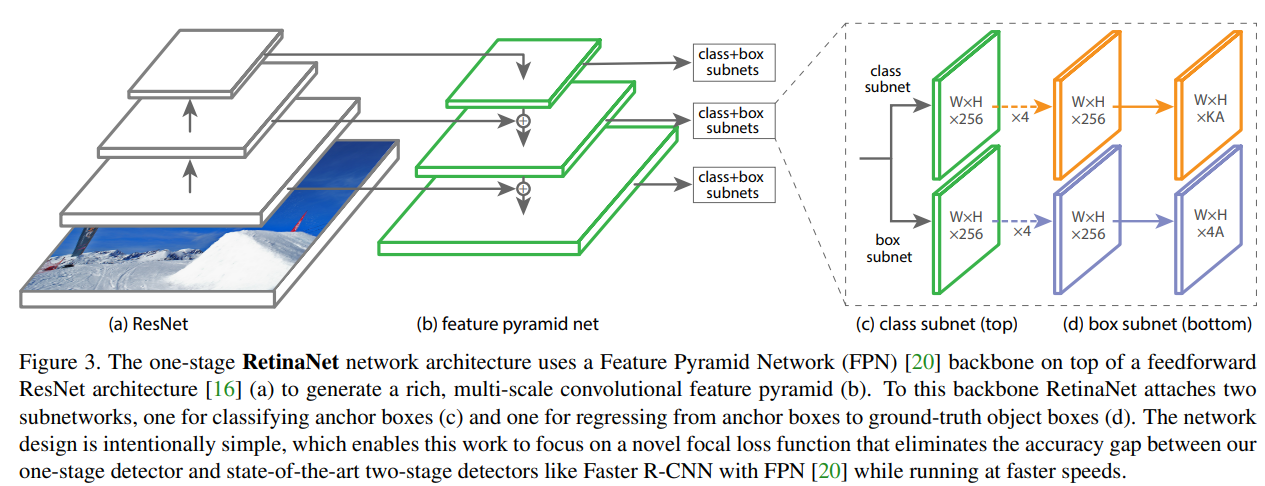
RetinaNet
RetinaNet은 하나의 backbone 네트워크와 두가지 서브 네트워크로 구성되어 있습니다. backbone에서는 입력 이미지의 피쳐 맵을 계산하고, 첫번째 서브 네트워크는 backbone에서 나온 아웃풋에 대해 객체 분류를 수행 / 두번째 서브 네트워크는 bbox regressor로 동작합니다. [6]
앞서 SSD에서도 간단하게 언급했지만, 배경으로 분류되는 negative 샘플이 너무 많기 때문에 hard negative mining과 같은 방법이 사용되고 있었습니다. RetinaNet은 Focal loss라는 새로운 개념을 제시하여 이러한 클래스 불균형 문제를 해결하고자 했습니다. 2-stage에서는 region proposal 과정에서 후보 위치를 빠르게 작은 숫자로 줄여주지만, 1-stage에서는 하나의 이미지에서 연산을 수행하면서 훨씬 많은 연산을 필요로 했습니다. 논문의 저자들은 맞는 클래스의 숫자가 증가함에 따라 손실이 급격하게 감소할 수 있도록 설계한 Focal loss를 제안했습니다.
Focal Loss
Focal loss는 논문의 제목처럼 RetinaNet에서 사용되는 핵심적인 아이디어입니다. 이진 분류 문제에서 사용했던 손실함수를 우선적으로 활용합니다. (아래 식 참고)
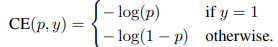
보통의 크로스 엔트로피 손실함수는 모든 예측 결과를 동등하게 예측하기 때문에 앞서 이야기한 것처럼 클래스 불균형이 발생하게 되면 학습이 제대로 이뤄지지 않을 우려가 있습니다. 이를 해결하기 위해 등장한 것이 가중치를 곱한 Balanced Cross Entropy가 있습니다. Focal Loss는 여기서 더 나아가, 쉬운 예시에는 작은 가중치 / 어려운 예시에는 큰 가중치를 곱할 수 있도록 파라미터를 추가하였습니다.
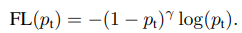
훈련
RetinaNet에서 훈련은 다음과 같은 과정으로 이뤄지게 됩니다.
1) 입력 이미지를 backbone에 입력해 피처 맵을 추출
2) 추출된 피처 맵을 서로 다른 스케일을 가진 피처 피라미드 추출 (논문에서는 ResNet + FPN 활용)
3) 피라미드 레별별 피처 맵을 서브 네트워크에 입력
- Classification 서브 네트워크에서는 분류 수행 (클래스 수 * 앵커 박스 수 만큼의 채널)
- bbox regression 서브 네트워크에서는 위치 조정 (x/y/w/h 4 * 앵커 박스 수만큼의 채널)
참고자료
[1] 송원호. "5) 1 stage Detectors". 부스트캠프 ai tech.
[2] https://herbwood.tistory.com/13
[3] Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi. "You Only Look Once : Unified, Real-Time Object Detection"
[4] Wei Liu et al. "SSD: Single Shot MultiBox Detector"
[5] https://herbwood.tistory.com/15
[6] https://paperswithcode.com/method/retinanet
[7] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollar. "Focal Loss for Dense Object Detection"
'Note > Deep Learning' 카테고리의 다른 글
| OCR 성능 평가 지표 알아보기 | DetEval, IoU, TIoU, CLEval (1) | 2024.11.07 |
|---|---|
| [OCR] 광학 문자 인식(OCR) 문제와 특징 (2) | 2024.11.02 |
| [OD] 2-Stage Detectors 변천사 | R-CNN 부터 Faster R-CNN 까지 (1) | 2024.10.11 |
| [OD] Neck의 기본 개념과 FPN, PANet, BiFPN 까지 정리 | Backbone의 여러 feature map을 합치는 방법 (0) | 2024.10.10 |
| [OD] 객체 탐지(Object Detection) 성능 판단 지표 정리 | IOU, mAP, FPS, FLOPS (0) | 2024.10.02 |