
[Seg] Fully Convolutional Networks (FCN) for Segmentation 정리
1. Fully Convolution Networks
1.1. 주요 특징
Convolution 네트워크는 컴퓨터 비전에서 획기적으로 성능 향상을 이끈 구조입니다. 다양한 피쳐 맵(feature map)을 만들어서 여러 컴퓨터 비전의 작업에 활용했습니다. Semantic segmentation에서도 convolution 네트워크를 활용하려는 시도가 있었고, 이에 대한 효시가 된 논문이 있습니다. [1]
해당 논문에서 제시하고 있는 Segmentation을 위한 FCN의 설계 주요 특징은 다음과 같습니다.
- 당시 좋은 성능을 내고 있던 VGG-16을 기본 구조(backbone)으로 사용
- Fully-connected layer를 Convolution layer로 대체
- Transposed convolution을 이용해 pixel-wise 예측을 수행
1.2. Convolution 연산이 필요한 이유
Fully-conneted layer는 모든 신경망들이 연결되어 1차원의 평탄화된 행렬을 통해 이미지를 분류하는데 사용되는 층입니다. 평탄화되어 있는만큼 위치에 대한 정보가 없어지기 때문에 이미지 정보를 담기에는 적절하지 않습니다.

반면에, Convolution은 필터/커널이 이동하면서 연산을 수행하기 때문에 위치 정보가 해치지 않은 상태로 피쳐 맵을 추출할 수 있고, 커널이 이동만 하면되기 때문에 입력의 크기에 상관이 없습니다.

1.3. Transposed convolution
Convolution 네트워크의 층을 통과할 때마다 패딩, 스트라이드 등에 따라 다르긴 하지만, 해상도가 갈수록 줄어듭니다. VGG의 경우 최종 층에서 나온 것은 1/32 수준인데, Segmentation에서는 원본 이미지에 표시를 해야 하기 때문에 복원을 위한 업샘플링 과정이 필요합니다.
각 요소의 값에 더 큰 커널을 적용하면 단순히 곱이되는 방식으로 커널 사이즈만큼의 행렬이 생성됩니다. 그것을 모든 요소에 적용하고 그 위치에 맞춘 다음 최종적으로 합을 진행하면 업샘플링이 가능합니다. 아래 그림은 2x2 입력값을 스트라이드 1의 커널 사이즈 3x3을 통해 4x4로 늘려주는 과정입니다. [3] 만약 더 큰 사이즈를 원할 경우 스트라이드를 키우면 더 큰 사이즈로 업샘플링이 가능할 것입니다. 이렇게 스트라이드가 1이 아닌 convolution을 strided convolution이라 합니다.
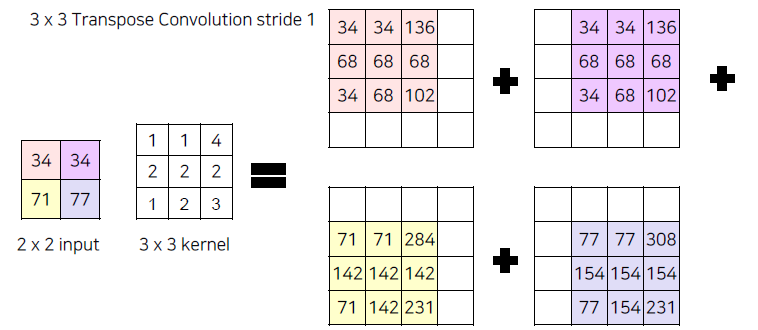
이러한 convolution 연산을 행렬로 표현하면 sparse한 커널 행렬을 역행렬을 구해서 곱해주면 업샘플링한 값을 구할 수 있습니다. 이는 전치(transpose)해서 우변에 곱하는 과정과 동일하기 때문에 transposed convolution이라고 합니다. 이러한 과정이 역으로 convolution한 것처럼 보인다고 해서 deconvolution이라는 명칭이 많이 활용되기는 하지만,엄밀한 의미에서 convolution의 역연산은 아니기 때문에 정확한 표기는 아닙니다.
Transposed convolution 역시 다른 convolution과 동일하게 학습이 되는 파라미터로 파이토치를 통해 구현이 가능합니다. 파이토치에서 구현하려면 아래와 같이 적을 수 있습니다.
torch.nn.ConvTranspose2d()
ConvTranspose2d — PyTorch 2.5 documentation
Shortcuts
pytorch.org
1.4. 구조
FCN의 구조는 기존의 convoltion 네트워크와 거의 동일합니다. 기본적인 convolution 구조에서 forward 연산을 통해 추론과 backward로 학습이 진행이되고, 맨 마지막 예측은 transpose convolution을 통해 pixel-wise 예측을 수행합니다.
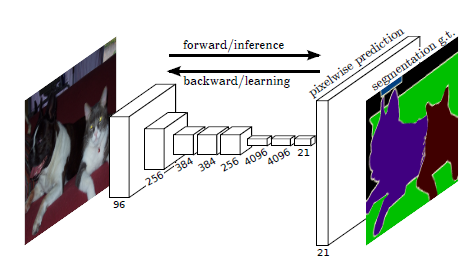
2. FCN에서 성능 향상 방법
2.1. stride 축소
하지만 진짜 구분해야 하는 ground truth에 비해 세밀함이 부족한 경우들이 많이 보였습니다. 아래 사진을 보면 경계선이 많이 사라진 것을 확인할 수 있는데, 이는 Max Pooling을 지나면서 손실된 정보들 때문입니다. 따라서 Pooling 층을 지나면서 잃어버린 정보에 대한 복원이 필요하고 손실이 발생하기 전에 정보를 합쳐서 정보를 보존하는 방식을 채택합니다.

정보를 합치는 방법은 ResNet에서도 언급된 skip connection (이전 층의 정보를 더하기) 방식으로 개선합니다. 최종층이 1/32이었기 때문에 최종 층에서 나온 Transpose Conv에서 나온 값(FCN-32s)과 1/16 층에서 나온 값을 1x1 Conv를 통과시켜서 합쳐서 예측을 수행한 것이 FCN-16s 입니다.
여기서 더 나아간 것이 FCN-16s 예측값과 1/8 층에서 나온 값을 1x1 conv 통과시켜서 합쳐 Transpose Conv를 통해 예측을 수행한 것이 FCN-8s 입니다. 위 이미지에서 확인할 수 있듯 이전 층의 정보를 합쳐줄수록 더욱 선명한 결과값이 나오는 것을 확인할 수 있습니다.

3. 참고자료
[1] Evan Shelhamer, Jonathan Long, Trevor Darrell. "Fully Convolutional Networks for Semantic Segmentation"
[2] https://builtin.com/machine-learning/fully-connected-layer
[3] 김현우. "Lecture 3. Semantic Segmentation의 기초와 이해". boostcamp ai tech.
[4] https://zzsza.github.io/data/2018/02/23/introduction-convolution/
'Note > Deep Learning' 카테고리의 다른 글
| [NLP] LLM의 효율적인 Fine-Tuning을 진행하는 방법 | Parameter Efficient Fine-Tuning, PEFT (0) | 2024.12.04 |
|---|---|
| [NLP] Large Language Model(LLM)의 학습 방법론 | LLM Pretrained Models (0) | 2024.12.03 |
| [Seg] Segmentation Task와 주요 평가지표(Dice) 정리 (0) | 2024.11.14 |
| OCR 성능 평가 지표 알아보기 | DetEval, IoU, TIoU, CLEval (0) | 2024.11.07 |
| [OCR] 광학 문자 인식(OCR) 문제와 특징 (2) | 2024.11.02 |